通过扩展dubbo的路由规则,实现通过不同入参调用不同的服务实例。(注意:需修改dubbo源码)
写在前面
dubbo.xsd完全没有router的配置,what the fuck!
注解也没关相关配置!!
官方文档如下:
走读源码:
首先dubbo APP启动时,便会在RegistryDirectory初始化时,针对每个消费者加载路由规则(不过看源码routers传入的都是null)。
并且每当注册中心相关数据有改变时会调用public synchronized void notify(List<URL> urls)方法,从注册中心同步消费者路由规则。
内部会调用protected void setRouters(List<Router> routers)来设置路由规则,且会append MockInvokersSelector路由器:routers.add(new MockInvokersSelector());
即dubbo目前的路由规则是通过注册中心将表达式等推送到客户端(其实还有脚本、文件等方式,此处不展开讲)
遇到问题
- 不修改消费者代码可以用新的提供者
- 不修改原来的提供者
- 通过增加数据库配置:key-rest url的KV对实现指定调度
基于REST的解决方案
这种方案本质上和dubbo没啥关系了。我大致画个架构图出来,就可以很明显看到其实现。
DB里面提供类似如下的配置(结合nginx):
| Key | Nginx | Real IP |
|---|---|---|
| P1 | 192.168.1.1:8080/P1_ng/ | 192.168.2.1:8080 |
| 192.168.2.2:8080 | ||
| P2 | 192.168.1.1:8080/P2_ng/ | 192.168.2.3:8080 |
| 192.168.2.4:8080 |
代码里面根据Key的不同,通过HTTP REST去调用nginx,然后nginx分发到不同IP下的实例。
架构图(图中并未画出多个nginx分流的情况,自行脑补之):
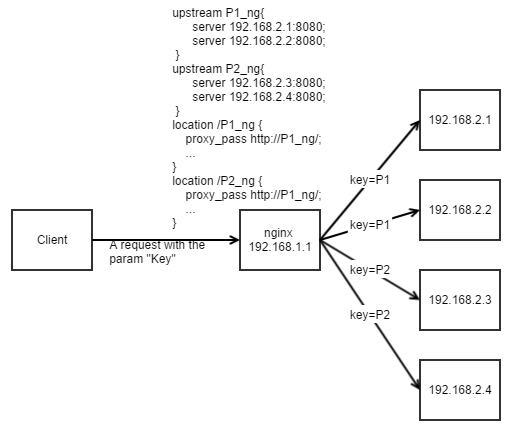
缺点
- 需要指定IP,而IP并不是恒定不变的(虽然生产环境很少改变,但是dev/st/uat就不一定了)
- 负载均衡:需要通过nginx实现服务端的负载均衡
- nginx HA:需要引入nginx HA方案
- 分流:通过多个nginx实例分流减少IO压力
基于扩展dubbo路由规则的解决方案
dubbo通过group,interface,version,三者决定是不是同一个服务。group暂不作考虑(目前没用到,那么整个服务注册便是一颗无根树)。配置version=”*”可以获取所有版本的提供者实例
针对上面的需求,有3个方案:
- 方案一:使用一个版本号,然后dubbo拿到该version的所有Invoker,然后通过提供者、消费者的IP进行匹配。
这样子便解决了上面除IP之外的所有问题。并且不需要修改dubbo源码。 - 方案二:修改dubbo原生路由规则,让其支持基于版本号的路由设定。
- 方案三:通过配置version=”*”,让dubbo可以通过某个注解获取所有的版本的所有Invoker。然后再扩展路由过滤。
方案一只需要研究dubbo的表达式怎么写就可以了;
方案二需要扩展路由,而具体可以参考方案三的实现;
方案三我会具体介绍,基本上包含了方案二的全部实现,但是注意方案二是通过注册中心推送规则。而方案三是通过注解注入相关规则。从而导致方案三的缺点:更新配置时需要更新所有实例的内存数据
解决方案如下:(这些只是顺便一提,不展开讲了)
- 配置所有实例共享,显然需要跨进程缓存:Redis、Zookeeper之类的。还可以利用watch实时更新(强一致性)
- 更新配置时,调用所有节点的方法更新配置数据
- 比如每个消费者都提供一个更新缓存的服务(作为提供者),然后利用dubbo的BroadcastCluster见Broadcast 广播调用更新(强一致性)
- 又比如通过Ecache,定时从数据库更新(最终一致性)
dubbo容错调度
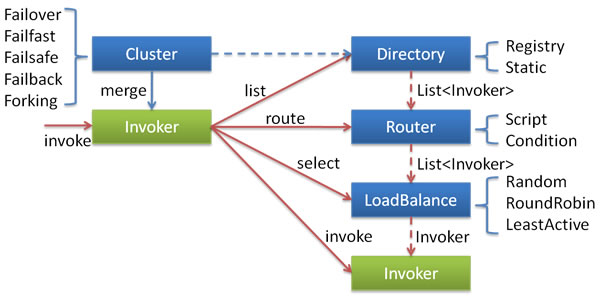
- Invoker:这里的Invoker是Provider的一个可调用Service的抽象,Invoker封装了Provider地址及Service接口信息。
- Directory:(SPI, Prototype, ThreadSafe)集群目录服务,Directory service。Directory代表多个Invoker,可以把它看成List
,但与List不同的是,它的值可能是动态变化的,比如注册中心推送变更。 - Cluster:Cluster将Directory中的多个Invoker伪装成一个Invoker,对上层透明,伪装过程包含了容错逻辑,调用失败后,重试另一个。
- Router:Router负责从多个Invoker中按路由规则选出子集,比如读写分离,应用隔离等。
- LoadBalance:LoadBalance负责从多个Invoker中选出具体的一个用于本次调用,选的过程包含了负载均衡算法,调用失败后,需要重选。
- 关于Router,有以下应用:
服务路由是治理的核心功能,它可以动态调整集群间的访问关系:
- 排除预发布机:
=> host != 172.22.3.91 - 白名单:(注意:一个服务只能有一条白名单规则,否则两条规则交叉,就都被筛选掉了),
host != 10.20.153.10,10.20.153.11 => - 黑名单:
host = 10.20.153.10,10.20.153.11 => - 服务寄宿在应用上,只暴露一部分的机器,防止整个集群挂掉:
=> host = 172.22.3.1*,172.22.3.2* - 为重要应用提供额外的机器:
application != kylin => host != 172.22.3.95,172.22.3.96 - 读写分离:
method != find*,list*,get*,is* => host = 172.22.3.97,172.22.3.98ormethod = find*,list*,get*,is* => host = 172.22.3.94,172.22.3.95,172.22.3.96 - 前后台分离:
application = bops => host = 172.22.3.91,172.22.3.92,172.22.3.93orapplication != bops => host = 172.22.3.94,172.22.3.95,172.22.3.96 - 隔离不同机房网段:
host != 172.22.3.* => host != 172.22.3.* - 提供者与消费者部署在同集群内,本机只访问本机的服务:
=> host = $host
而路由规则的配置通常是通过监控中心or治理中心的页面完成,也可以通过RegistryFactory写入。
- 排除预发布机:
dubbo源码解析(可以不看)
以下可以概括为源码乱读= =||
ReferenceConfig
|
|
留意:init()的以下代码:
但是protected static void appendProperties(AbstractConfig config)是AbstractConfig的方法,入参也是AbstractConfig里面,所以appendProperties不能追加ReferenceConfig的参数。
AnnotationBean
AnnotationBean extends AbstractConfig用于包装处理com.alibaba.dubbo.config.annotation.Reference和com.alibaba.dubbo.config.annotation.Service注解。
通过AnnotationBean的方法private Object refer(Reference reference, Class<?> referenceClass)解析AnnotationBean成private final ConcurrentMap<String, ReferenceBean<?>> referenceConfigs = new ConcurrentHashMap<String, ReferenceBean<?>>();
在refer方法中,对consumer的解析执行了2次(此处甚是迷惑):
|
|
AbstractDirectory
AbstractDirectory是增加router的Directory。
com.alibaba.dubbo.rpc.cluster.directory.AbstractDirectory
RegistryDirectory
RegistryDirectory: 注册目录服务,通过此类可以获取消费者消费的提供者的所有实例Invokers
com.alibaba.dubbo.registry.integration.RegistryDirectory
|
|
ConditionRouter
ConditionRouter:条件路由,关于条件路由的定义以及正则匹配,具体见这里,源码是:Map<String, MatchPair> parseRule(String rule)
com.alibaba.dubbo.rpc.cluster.router.condition.ConditionRouter
|
|
修改源码(此步才是关键)
dubbo运行流程
先理清一下dubbo的运行流程:
- Spring扫描注解得到所有的
AnnotationBean。即@Refernce和@Service注解的引用 - 对每一个
AnnotationBean执行:private Object refer(Reference reference, Class<?> referenceClass),得到ConcurrentMap<String, ReferenceBean<?>> referenceConfigs和Set<ServiceConfig<?>> serviceConfigs = new ConcurrentHashSet<ServiceConfig<?>>()。这两个都是AnnotationBean的属性。(在这里查找对注解的解析代码,层层引用,可以定位到:com.alibaba.dubbo.config.AbstractConfig#appendAnnotation) - 从
ReferenceConfig<T>调用get()方法,会进行init()操作。ReferenceConfig会被缓存,所以消费者代理也会被缓存(消费者代理是ReferenceConfig的属性)。里面有下面一段源码(留意我写的注释):
|
|
- 通过带来调用服务提供者
注解配置解析
首先,路由器应该是可配置的,那么就要添加解析路由器的相关代码。
dubbo是客户端负载均衡,理论上路由的判断应放在客户端执行,所以这里我本来打算修改消费者相关的代码。
com.alibaba.dubbo.config.ReferenceConfig 的private void init()方法初始化并解析消费者的配置。
但注意:如果在com.alibaba.dubbo.config.AbstractReferenceConfig 抽象类添加router属性,会有点问题:(AbstractInterfaceConfig属于提供者和消费者共同的配置接口,而且从注册中心加载URL的方法protected List<URL> loadRegistries(boolean provider)由它提供,所以扩展路由代码写在AbstractInterfaceConfig里面):
|
|
先修改注解:
增加routers的配置参数:
com.alibaba.dubbo.config.annotation.Reference
注意到:在ReferenceConfig的构造方法里会调用appendAnnotation来解析注解(注:对于数组合会并成’,’分隔的字符串)。
修改com.alibaba.dubbo.config.AbstractConfig#appendAnnotation:
经过了上面的一步,注解的参数已经被解析到AbstractConfig里面了。
router设置
注意:dubbo的router扩展如下(这种方式是JDK SPI):
- 写2个类,分别实现Router和RouterFactory。RouterFactory假设是
com.alibaba.dubbo.rpc.cluster.router.xxxRouterFactory - 然后让dubbo可以识别routerName是xxx的路由。
|
|
- 设置路由,通常在初始化
AbstractDirectory时设置,或由RegistryDirectory的notify通知更新。
|
|
那么问题来了,URL是怎么生成的呢?
|
|
到此为止,在URL添加上router即可,如下:
|
|
修改的具体代码
Github查看
PS:一看提交记录,其实才改了几行代码,但是其中需要做的准备工作感觉很多。这也算是Coding的乐趣之一了:)
使用示例
- KeyRouter:包括工厂类和实例类
- JDK SPI:注意文件名和位置
- 注解引入router:12(version = "*",router = "keyRouter")private HelloRest helloRest3;
关于XML配置文件
这里并没有扩展XML配置文件,有兴趣可以自行扩展。或许有一天我会补上这儿的代码。
其实原理上大体差不多。区别应该是初始化的时候读的是XML。
那么关注的类是:
NamespaceHandlerBeandefinitionParserDubboBeanDefinitionParserDubboNamespaceHandler
TODO
从注册中心推送的routers是否会影响现有的routers?覆盖/被覆盖/叠加/抛异常?待研究。
写在最后
dubbo的确是优秀的框架,一开始我的设计是重写负载均衡器,然后走读代码+官方文档,才发现dubbo早已考虑到了这些需求。
dubbo提供了router层,稍作变动问题便可以迎刃而解。
很感谢阿里的开源。:)