术语概念
节点状态
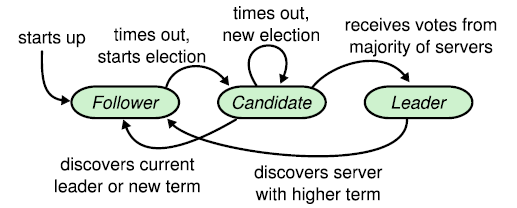
在集群中,每个节点可能具有一下3中状态
- Follower:从节点
- Candidate:候选人节点,Follower->Leader的中间态
- Leader:主节点,在集群中有且只有1个合法Leader;如果存在多个Leader,则term最大的Leader是合法Leader。
选主
- Heartbeat Interval:Leader向Follower发送心跳的间隔
- Election Timemout/Heartbeat Timeout:我认为这2个Timeout属于同一个东西。Follower失去了与Leader的心跳(在某个时间内没有收到Leader的心跳消息),则会随机设置ET=[150,300]ms(随机数可以减少多个Node同时成为Candidate的几率)。election timemout后,该节点会成为Candidate,并开始一轮election term,请求其他节点为其投票。
- Election Term:选主有效期,带有版本号,election term版本号最高的Leader为合法Leader。每轮选举每个节点只能投票一次,并重置election timemout。
日志复制
- LogEntry/AppendEntry:理解为undo log和redo log,并且认为LogEntry一旦写入磁盘便永不改变(持久化),并且需要保持log的顺序。
其他
- term:我理解为租约有效期(参考Lease机制)。
集群启动
假设存在1个只有3个节点的集群,分别为A、B、C
- <1>A、B、C的初始状态均为Follower
- <2>由于没有Leader,Follower不能收到Leader的心跳。然后某个Follower会成为Candidate。假设A成为了Candidate,则A会请求B、C投票让A成为Leader(A会给自己投一票,每个节点在一轮投票中只能投票1次)。一个Candidate如果获得了集群大多数节点的投票,则成为Leader。此过程成为选主(Leader Selection)。
- <3>所有交互现在通过Leader完成(具体参看日志复制章节的写操作示意图)。
选主(Leader Election)
Leader定期(Heartbeat Interval)向Followers发送心跳,如下图,假设Leader和Followers之间发生了网络分区,
Followers无法收到Leader的心跳,等待Election Timeout时间后,Followers会发起新的一轮选主(Election Term)。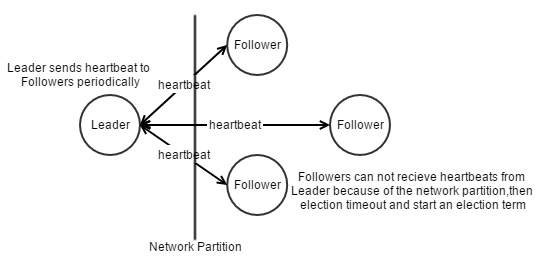
选举开始,Candidate初始化并维护term和Vote Count(投票数量),然后会投票给自己。
之后将term发送给Followers,请求他们投票。如果该轮选举未投票,Follower会投票给该Candidate。
一旦Candidate获得了集群大多数Followers的投票,则Candidate成为Leader。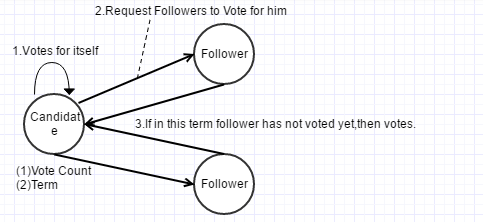
- 如何减少多个Follower成为Candidate?
Election Timeout随机设置
- 如果同时存在多个Candidate呢?
投票完毕,如果Candidates票数相等,则重置Election Timeout,进行下一轮选主。
- 如何保证一轮选举只产生一个Leader?
每个Follower在同一个Election Term只能投票一次,获得大多数投票的Candidate正式成为Leader
- 还有疑问:集群如何维护term的全局递增序列?
无责任猜想:在实际中,通过redis,zookeeper等方式实现,比如redis的incr命令,又或者分布式锁。
日志复制(Log Replication)
Raft算法必须认为log一旦写入,便是持久的(即不可改变),这是前提。
log也应该是有序的(如何保证有序性不展开讲,不过如果log乱序,一致性没有保证,比如先删后写,和先写后删完全是不一样的最终结果)。
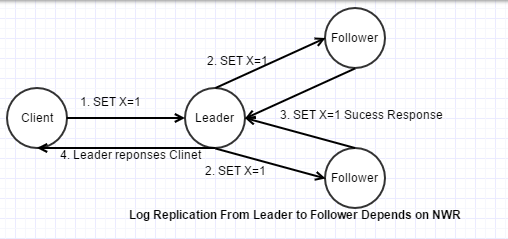
以一次写入操作为例:
- Client发送请求给Leader,设置X=1。Leader写入undo log和redo log(LogEntry/AppendEntry),但事务并未提交。
- Leader将x=1的LogEntry复制至Follower
- Follower响应leader,告知写入成功(这里遵循NWR规则)
- Leader响应Client,告知些如此成功。
- 如果网络分区将集群分为多个子集群,如何保证一致性?
每个子集群都会有一个Leader,当网络恢复后,在整个集群之中,term最高的Leader为合法Leader。其他Leader产生的log会被回滚(因为无法获得大部分节点的log写入确认,所以所有的log都不能提交),然后同步唯一的合法Leader的log至整个集群。含有大部分节点的子集群依然正常提供服务,但是含有少部分节点的子集群永远无法提交事务,丧失部分可用性。
此处就是典型的牺牲可用性来换取一致性。所以Raft是一个CP算法。
疑问:根据Raft:Understandable Distributed Consensus介绍,网络分区分为大小集群,分区集群独立选主,但是提交log却按照整个进群的节点进行写入确认。还有如何保证网络分区时如何保证大的子集群的的term一定高于小的子集群?[待研究]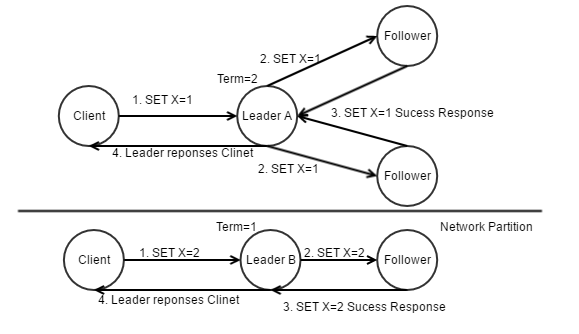
Raft的CAP分析
Raft是一个CP算法,具体参看日志复制章节介绍。
引用
Raft:Understandable Distributed Consensus
In Search of an Understandable Consensus Algorithm