Tomcat调优、JVM调优与垃圾回收,资料主要来源于互联网,整理下来备用。不过感觉描述多有不同,且思且看。
JVM运行时数据区
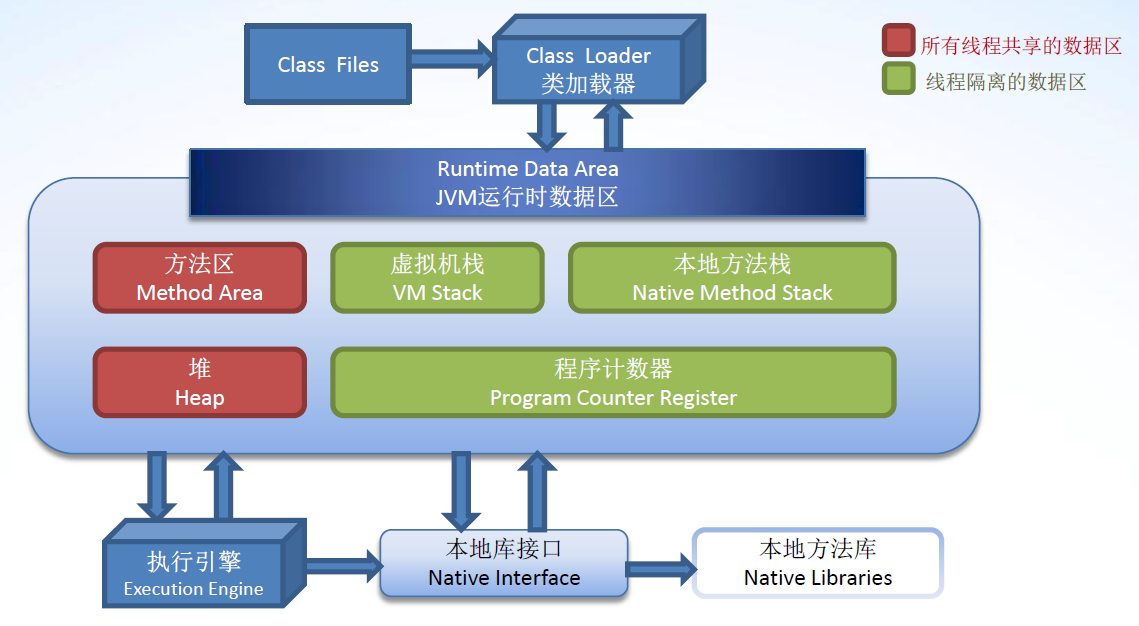
- 程序计数器
程序计数器是一块较小的内存空间,它可以看成是当前线程所执行的字节码的行号指示器。程序计数器记录线程当前要执行的下一条字节码指令的地址。由于Java是多线程的,所以为了多线程之间的切换与恢复,每一个线程都需要单独的程序计数器,各线程之间互不影响。这类内存区域被称为“线程私有”的内存区域。
由于程序计数器只存储一个字节码指令地址,故此内存区域没有规定任何OutOfMemoryError情况。 - 虚拟机栈
Java虚拟机栈也是线程私有的,它的生命周期与线程相同。虚拟机栈描述的是Java方法执行的内存模型:每个方法在执行时都会创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态链接、方法出口等信息。
一个栈帧就代表了一个方法执行的内存模型,虚拟机栈中存储的就是当前执行的所有方法的栈帧(包括正在执行的和等待执行的)。每一个方法从调用直至执行完成的过程,就对应着一个栈帧在虚拟机中入栈到出栈的过程。我们平时所说的“局部变量存储在栈中”就是指方法中的局部变量存储在代表该方法的栈帧的局部变量表中。而方法的执行正是从局部变量表中获取数据,放至操作数栈上,然后在操作数栈上进行运算,再将运算结果放入局部变量表中,最后将操作数栈顶的数据返回给方法的调用者的过程。
虚拟机栈可能出现两种异常:由线程请求的栈深度过大超出虚拟机所允许的深度而引起的StackOverflowError异常;以及由虚拟机栈无法提供足够的内存而引起的OutOfMemoryError异常。 - 本地方法栈
本地方法栈与虚拟机栈类似,他们的区别在于:本地方法栈用于执行本地方法(Native方法);虚拟机栈用于执行普通的Java方法。在HotSpot虚拟机中,就将本地方法栈与虚拟机栈做在了一起。
本地方法栈可能抛出的异常同虚拟机栈一样。 - 堆
Java堆是Java虚拟机所管理的内存中最大的一块。Java堆是被所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例:所有的对象实例以及数组都要在堆上分配(The heap is the runtime data area from which memory for all class instances and arrays is allocated)。但Class对象比较特殊,它虽然是对象,但是存放在方法区里。在下面的方法区一节会介绍。Java堆是垃圾收集器(GC)管理的主要区域。现在的收集器基本都采用分代收集算法:新生代和老年代。而对于不同的”代“采用的垃圾回收算法也不一样。一般新生代使用复制算法;老年代使用标记整理算法。对于不同的”代“,一般使用不同的垃圾收集器,新生代垃圾收集器和老年代垃圾收集器配合工作。
Java堆可以是物理上不连续的内存空间,只要逻辑上连续即可。Java堆可能抛出OutOfMemoryError异常。 - 运行时常量池
运行时常量池是方法区的一部分,关于运行时常量池的介绍,参考:String放入运行时常量池的时机与String.intern()方法解惑
- 方法区
方法区与Java堆一样,是各个线程共享的内存区域。它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
所有的字节码被加载之后,字节码中的信息:类信息、类中的方法信息、常量信息、类中的静态变量等都会存放在方法区。正如其名字一样:方法区中存放的就是类和方法的所有信息。此外,如果一个类被加载了,就会在方法区生成一个代表该类的Class对象(唯一一种不在堆上生成的对象实例)该对象将作为程序访问方法区中该类的信息的外部接口。有了该对象的存在,才有了反射的实现。
在Java7之前,HotSpot虚拟机中将GC分代收集扩展到了方法区,使用永久代来实现了方法区。这个区域的内存回收目标主要是针对常量池的回收和对类型的卸载。但是在之后的HotSpot虚拟机实现中,逐渐开始将方法区从永久代移除。Java7中已经将运行时常量池从永久代移除,在Java 堆(Heap)中开辟了一块区域存放运行时常量池。而在Java8中,已经彻底没有了永久代,将方法区直接放在一个与堆不相连的本地内存区域,这个区域被叫做元空间。 直接内存/堆外内存
JDK1.4中引用了NIO,并引用了Channel与Buffer,可以使用Native函数库直接分配堆外内存,并通过一个存储在Java堆里面的DirectByteBuffer对象作为这块内存的引用进行操作。
如上文介绍的:Java8以及之后的版本中方法区已经从原来的JVM运行时数据区中被开辟到了一个称作元空间的直接内存区域。永久代(元空间)数据
在Java虚拟机(JVM)内部,class文件中包括类的版本、字段、方法、接口等描述信息,还有运行时常量池,用于存放编译器生成的各种字面量和符号引用。
JVM垃圾回收
What/When/How
JVM的GC需要了解的3个问题:
- 哪些东西是Garbage?
通过垃圾标识算法:“引用计数算法”/“可达性分析算法”标记的对象便是等待被回收的“垃圾”对象
- 什么时候触发Collection?
- 触发Full GC条件:
- 调用
System.gc()时被建议执行Full GC,但不一定会发生GC。 - 老年代空间不足,Full GC
- 方法区空间不足,Full GC
- Young GC后进入老年代的平均大小大于老年代的可用内存
- 由Eden区、From Survivor区向To Survivor区复制时,对象大小大于To Survivor可用内存,则把该对象转存到老年代,且老年代的可用内存小于该对象大小
- 调用
- 触发Young GC条件:
- 当Eden区满时,Young GC
- 触发Full GC条件:
- Garbage Collection做了什么?
释放“垃圾”对象的内存空间。
GC类型
- Partial GC:并不收集整个GC堆的模式
- Young GC:只收集young gen的GC
- Old GC:只收集old gen的GC。只有CMS的concurrent collection是这个模式
- Mixed GC:收集整个young gen以及部分old gen的GC。只有G1有这个模式
- Full GC:收集整个堆,包括young gen、old gen、perm gen(如果存在的话)等所有部分的模式。
最简单的分代式GC策略,按HotSpot VM的serial GC的实现来看,触发条件是:
- young GC:当young gen中的eden区分配满的时候触发。注意young GC中有部分存活对象会晋升到old gen,所以young GC后old gen的占用量通常会有所升高。
- full GC:当准备要触发一次young GC时,如果发现统计数据说之前young GC的平均晋升大小比目前old gen剩余的空间大,则不会触发young GC而是转为触发full GC(因为HotSpot VM的GC里,除了CMS的concurrent collection之外,其它能收集old gen的GC都会同时收集整个GC堆,包括young gen,所以不需要事先触发一次单独的young GC);或者,如果有perm gen的话,要在perm gen分配空间但已经没有足够空间时,也要触发一次full GC;或者System.gc()、heap dump带GC,默认也是触发full GC。
垃圾标识算法
引用计数法
Java堆中每个Object都有一个计数器,Object被引用时计数器+1,当Object被置为null或者离开作用域时计数器-1.计数器为0的Object会被标识为“垃圾”对象。但此方法无法解决对象间循环引用的问题。
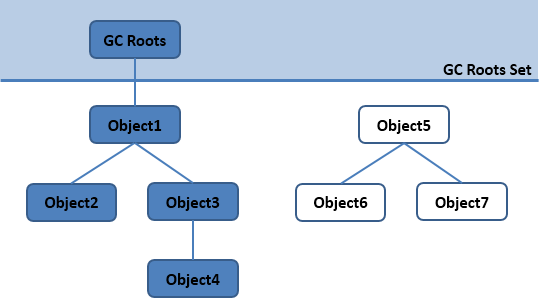
可达性分析算法
JVM以一系列GCRoots为根节点,从GCRoot向下搜索,搜索的路径称之为引用链。不在引用链上的对象(无法搜索到的对象)便是“垃圾”对象。
在Java语言中,可作为GC Roots的对象包括下面几种:
- 虚拟机栈(栈帧中的本地变量表)中引用的对象。
- 方法区中类静态属性引用的对象。
- 方法区中常量引用的对象。
- 本地方法栈中JNI(即一般说的Native方法)引用的对象。
可达性分析算法会造成GC停顿,因为此项工作必须在一个一致性的快照中进行,此时所有Java线程停止执行(否则可达性会在分析过程中发生变化)。Sun称此为Stop The World。
Java的引用方式
- 强引用(StrongReference):我们常用的复制引用便是强引用,强引用的对象不会被JVM回收。内存不足时,JVM抛出OOM异常。
- 软引用(SoftReference):JVM内存不足时会优先回收
- 弱引用(WeakReference):JVM无论内存是否充足,在GC的时候都会回收弱引用对象。
- 虚引用(PhantomReference):虚引用和软引用、弱引用不同,它并不影响对象的生命周期。如果一个对象与虚引用关联,则跟没有引用与之关联一样,在任何时候都可能被垃圾回收器回收。虚引用与软引用和弱引用的一个区别在于:虚引用必须和引用队列 (ReferenceQueue)联合使用。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。
- 理解软引用和弱引用:被软引用关联的对象只有在内存不足时才会被回收,而被弱引用关联的对象在JVM进行垃圾回收时总会被回收。针对上面的特性,软引用适合用来进行缓存,当内存不够时能让JVM回收内存,弱引用能用来在回调函数中防止内存泄露。因为回调函数往往是匿名内部类,隐式保存有对外部类的引用,所以如果回调函数是在另一个线程里面被回调,而这时如果需要回收外部类,那么就会内存泄露,因为匿名内部类保存有对外部类的强引用。
| 级别 | 什么时候被垃圾回收 | 用途 | 生存时间 |
|---|---|---|---|
| 强引用 | 从来不会 | 对象的一般状态 | JVM停止运行时终止 |
| 软引用 | 在内存不足时 | 对象缓存 | 内存不足时终止 |
| 弱引用 | 在垃圾回收时 | 对象缓存 | GC运行后终止 |
| 虚引用 | Unknown | Unknown | Unknown |
垃圾回收算法
- 标记/清除法Mark-Sweep
- 标记:标记“垃圾”对象
- 清除:清除“垃圾”对象,释放内存
- 优点:GC速度快
- 缺点:产生大量的内存碎片(即内存空间在物理上不连续)。可能会导致申请大对象时由于没有足够的连续内存空间而触发GC操作。
- 标记/复制法mark-Copy
- 标记:标记“垃圾”对象
- 复制:将内存等量分为2块:A和B。当A的内存消耗完毕,把A的非垃圾对象复制到B,然后清空A所有对象。
- 优点:不用考虑内存碎片化。
- 缺点:占用多一倍的内存。
- 标记/整理法Mark-Compact
- 标记:标记“垃圾”对象
- 整理:让非垃圾对象都向一端移动,垃圾对象向另一端移动。最后清除非垃圾对象边界外的所有对象,释放内存空间。
- 优点:不用考虑内存碎片化。
- 缺点:GC时间长,因为需要移动对象。
分代回收算法
分代回收法是垃圾回收算法的综合应用,根据不同的内存区域执行不同的垃圾回收算法。各种垃圾收集器的差异在此不讨论。
基本概念
- 理论支持:经验得出——“大部分的对象在生成后马上就变成了垃圾,很少有对象能活得很久”。
- 分代垃圾回收将刚生成的对象称为新生代,达到一定年龄(进过一次GC即一岁)的对象称为老年代,不同代的对象使用不同回收算法。
- 新生代对象执行GC称为新生代GC(Young GC)。
- 新生代对象存活一定次数GC将晋升到老年代,老年代的GC称为老年代GC(Old GC)。
GC机制
对于用可达性分析法搜索不到的对象,GC并不一定会回收该对象。要完全回收一个对象,至少需要经过两次标记的过程。 - 第一次标记:对于一个没有其他引用的对象,筛选该对象是否有必要执行
finalize()方法,如果没有执行必要,则意味可直接回收。(筛选依据:筛选的条件是此对象是否有必要执行finalize()方法。当对象没有覆盖finalize()方法,或者finalize()方法已经被虚拟机调用过,虚拟机将这两种情况都视为“没有必要执行”,即意味着直接回收。需要注意finalize方法在对象的声明周期内只能被执行一次)。 - 第二次标记:如果被筛选判定为有必要执行,则会放入FQueue队列,并自动创建一个低优先级的finalize线程来执行释放操作。如果在一个对象释放前被其他对象引用,则该对象会被移出FQueue队列。
堆内存分代
- 年轻代(Young Generation):年轻代分为3个区
- Eden区:新生对象进入
- From Survivor区:上次GC存活的年轻代对象
- To Survivor区:Young GC时,复制Eden区,From Survivor区存活的对象至To Survivor区。之后From/To互换。
默认分配比例为:Eden : From Survivor : To Survivor = 8:1:1
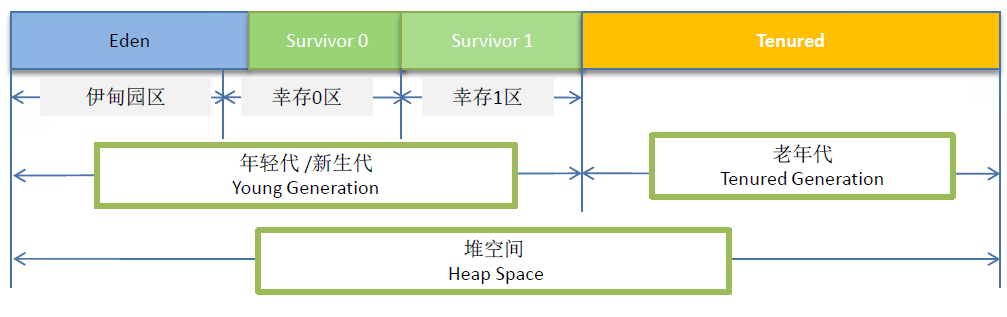
- 老年代(Old Generation):
- 长期存活对象,默认Age=15(每GC一次Age+1)
- 大对象直接进入
- Young GC后,Survivor区放不下
PS:持久代(PermanentGeneration)在JDK8已经修改为Metaspace。
分代回收
并不一定如此,不同的垃圾收集器可能存在不同的GC算法。
- Young GC:标记/复制算法
- Old GC:标记/清除算法
垃圾收集器
- CMS
- G1
- Parallel Scavenge
- ParNew
- Serial Old(MSC)
- Parallel Old
- Serial
JVM调优参数表
- -server/-client:
- -server:x64默认模式,特点是启动速度比较慢,但运行时性能和内存管理效率很高,适用于生产环境
- -client:x86默认模式,特点是启动速度快,但运行时性能和内存管理效率不高,通常用于客户端应用程序或开发调试
- -Xms:表示 Java 初始化堆的大小,-Xms 与-Xmx 设成一样的值,避免 JVM 反复重新申请内存,导致性能大起大落,默认值为物理内存的 1/64,默认(MinHeapFreeRatio参数可以调整)空余堆内存小于 40% 时,JVM 就会增大堆直到 -Xmx 的最大限制。
- -Xmx:表示最大 Java 堆大小,当应用程序需要的内存超出堆的最大值时虚拟机就会提示内存溢出,并且导致应用服务崩溃,因此一般建议堆的最大值设置为可用内存的最大值的80%。如何知道我的 JVM 能够使用最大值,使用 java -Xmx512M -version 命令来进行测试,然后逐渐的增大 512 的值,如果执行正常就表示指定的内存大小可用,否则会打印错误信息,默认值为物理内存的 1/4,默认(MinHeapFreeRatio参数可以调整)空余堆内存大于 70% 时,JVM 会减少堆直到-Xms 的最小限制。
- -Xmn:新生代的内存空间大小,注意:此处的大小是(eden+ 2 survivor space)。与 jmap -heap 中显示的 New gen 是不同的。整个堆大小 = 新生代大小 + 老生代大小 + 永久代大小。在保证堆大小不变的情况下,增大新生代后,将会减小老生代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的 3/8。
- -Xss:表示每个 Java 线程堆栈大小,JDK 5.0 以后每个线程堆栈大小为 1M,以前每个线程堆栈大小为 256K。根据应用的线程所需内存大小进行调整,在相同物理内存下,减小这个值能生成更多的线程,但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在 3000~5000 左右。一般小的应用, 如果栈不是很深, 应该是128k 够用的,大的应用建议使用 256k 或 512K,一般不易设置超过 1M,要不然容易出现out ofmemory。这个选项对性能影响比较大,需要严格的测试。
- -XX:NewSize:设置新生代内存大小。
- -XX:MaxNewSize:设置最大新生代新生代内存大小
- -XX:PermSize:设置持久代内存大小
-XX:MaxPermSize:设置最大值持久代内存大小,永久代不属于堆内存,堆内存只包含新生代和老年代。注:JDK8已经将持久代更名为元空间Metaspace
JDK 8:Metaspace默认为无限制,并且会自动调节Metaspace的大小。当然也可以通过
-XX:MaxMetaspaceSize来指定大小。JDK7还将常量池从永久代(位于方法区)移出到堆。-XX:+AggressiveOpts:作用如其名(aggressive),启用这个参数,则每当 JDK 版本升级时,你的 JVM 都会使用最新加入的优化技术(如果有的话)。
- -XX:+UseBiasedLocking:启用一个优化了的线程锁,我们知道在我们的appserver,每个http请求就是一个线程,有的请求短有的请求长,就会有请求排队的现象,甚至还会出现线程阻塞,这个优化了的线程锁使得你的appserver内对线程处理自动进行最优调配。
- -XX:+DisableExplicitGC:在程序代码中不允许有显示的调用“System.gc()”。每次在到操作结束时手动调用 System.gc() 一下,付出的代价就是系统响应时间严重降低,就和关于 Xms,Xmx 里的解释的原理一样,这样去调用 GC 导致系统的 JVM 大起大落。
- -XX:+UseConcMarkSweepGC:设置年老代为并发收集,即 CMS gc,这一特性只有 jdk1.5后续版本才具有的功能,它使用的是 gc 估算触发和 heap 占用触发。我们知道频频繁的 GC 会造面 JVM的大起大落从而影响到系统的效率,因此使用了 CMS GC 后可以在 GC 次数增多的情况下,每次 GC 的响应时间却很短,比如说使用了 CMS GC 后经过 jprofiler 的观察,GC 被触发次数非常多,而每次 GC 耗时仅为几毫秒。
- -XX:+UseParNewGC:对新生代采用多线程并行回收,这样收得快,注意最新的 JVM 版本,当使用 -XX:+UseConcMarkSweepGC 时,-XX:UseParNewGC 会自动开启。因此,如果年轻代的并行 GC 不想开启,可以通过设置 -XX:-UseParNewGC 来关掉。
- -XX:MaxTenuringThreshold:设置垃圾最大年龄。如果设置为0的话,则新生代对象不经过 Survivor 区,直接进入老年代。对于老年代比较多的应用(需要大量常驻内存的应用),可以提高效率。如果将此值设置为一 个较大值,则新生代对象会在 Survivor 区进行多次复制,这样可以增加对象在新生代的存活时间,增加在新生代即被回收的概率,减少Full GC的频率,这样做可以在某种程度上提高服务稳定性。该参数只有在串行 GC 时才有效,这个值的设置是根据本地的 jprofiler 监控后得到的一个理想的值,不能一概而论原搬照抄。
- -XX:+CMSParallelRemarkEnabled:在使用 UseParNewGC 的情况下,尽量减少 mark 的时间。
- -XX:+UseCMSCompactAtFullCollection:在使用 concurrent gc 的情况下,防止 memoryfragmention,对 live object 进行整理,使 memory 碎片减少。
- -XX:LargePageSizeInBytes:指定 Java heap 的分页页面大小,内存页的大小不可设置过大, 会影响 Perm 的大小。
- -XX:+UseFastAccessorMethods:使用 get,set 方法转成本地代码,原始类型的快速优化。
- -XX:+UseCMSInitiatingOccupancyOnly:只有在 oldgeneration 在使用了初始化的比例后 concurrent collector 启动收集。
- -Duser.timezone=Asia/Shanghai:设置用户所在时区。
- -Djava.awt.headless=true:这个参数一般我们都是放在最后使用的,这全参数的作用是这样的,有时我们会在我们的 J2EE 工程中使用一些图表工具如:jfreechart,用于在 web 网页输出 GIF/JPG 等流,在 winodws 环境下,一般我们的 app server 在输出图形时不会碰到什么问题,但是在linux/unix 环境下经常会碰到一个 exception 导致你在 winodws 开发环境下图片显示的好好可是在 linux/unix 下却显示不出来,因此加上这个参数以免避这样的情况出现。
- -XX:CMSInitiatingOccupancyFraction:当堆满之后,并行收集器便开始进行垃圾收集,例如,当没有足够的空间来容纳新分配或提升的对象。对于 CMS 收集器,长时间等待是不可取的,因为在并发垃圾收集期间应用持续在运行(并且分配对象)。因此,为了在应用程序使用完内存之前完成垃圾收集周期,CMS 收集器要比并行收集器更先启动。因为不同的应用会有不同对象分配模式,JVM 会收集实际的对象分配(和释放)的运行时数据,并且分析这些数据,来决定什么时候启动一次 CMS 垃圾收集周期。这个参数设置有很大技巧,基本上满足(Xmx-Xmn)(100-CMSInitiatingOccupancyFraction)/100 >= Xmn 就不会出现 promotion failed。例如在应用中 Xmx 是6000,Xmn 是 512,那么 Xmx-Xmn 是 5488M,也就是老年代有 5488M,CMSInitiatingOccupancyFraction=90 说明老年代到 90% 满的时候开始执行对老年代的并发垃圾回收(CMS),这时还 剩 10% 的空间是 548810% = 548M,所以即使 Xmn(也就是新生代共512M)里所有对象都搬到老年代里,548M 的空间也足够了,所以只要满足上面的公式,就不会出现垃圾回收时的 promotion failed,因此这个参数的设置必须与 Xmn 关联在一起。
- -XX:+CMSIncrementalMode:该标志将开启 CMS 收集器的增量模式。增量模式经常暂停 CMS 过程,以便对应用程序线程作出完全的让步。因此,收集器将花更长的时间完成整个收集周期。因此,只有通过测试后发现正常 CMS 周期对应用程序线程干扰太大时,才应该使用增量模式。由于现代服务器有足够的处理器来适应并发的垃圾收集,所以这种情况发生得很少,用于但 CPU情况。
- -XX:NewRatio:年轻代(包括 Eden 和两个 Survivor 区)与年老代的比值(除去持久代),-XX:NewRatio=4 表示年轻代与年老代所占比值为 1:4,年轻代占整个堆栈的 1/5,Xms=Xmx 并且设置了 Xmn 的情况下,该参数不需要进行设置。
- -XX:SurvivorRatio:Eden 区与 Survivor 区的大小比值,设置为 8,表示 2 个 Survivor 区(JVM 堆内存年轻代中默认有 2 个大小相等的 Survivor 区)与 1 个 Eden 区的比值为 2:8,即 1 个 Survivor 区占整个年轻代大小的 1/10。
- -XX:+UseSerialGC:设置串行收集器。
- -XX:+UseParallelGC:设置为并行收集器。此配置仅对年轻代有效。即年轻代使用并行收集,而年老代仍使用串行收集。
- -XX:+UseParallelOldGC:配置年老代垃圾收集方式为并行收集,JDK6.0 开始支持对年老代并行收集。
- -XX:ConcGCThreads:早期 JVM 版本也叫-XX:ParallelCMSThreads,定义并发 CMS 过程运行时的线程数。比如 value=4 意味着 CMS 周期的所有阶段都以 4 个线程来执行。尽管更多的线程会加快并发 CMS 过程,但其也会带来额外的同步开销。因此,对于特定的应用程序,应该通过测试来判断增加 CMS 线程数是否真的能够带来性能的提升。如果还标志未设置,JVM 会根据并行收集器中的 -XX:ParallelGCThreads 参数的值来计算出默认的并行 CMS 线程数。
- -XX:ParallelGCThreads:配置并行收集器的线程数,即:同时有多少个线程一起进行垃圾回收,此值建议配置与 CPU 数目相等。
- -XX:OldSize:设置 JVM 启动分配的老年代内存大小,类似于新生代内存的初始大小 -XX:NewSize。
- 其他更多的参数
jstack/jmap/jstat/jps/jhat
现实企业级Java开发中,有时候我们会碰到下面这些问题:OutOfMemoryError,内存不足,内存泄露,线程死锁,锁争用(Lock Contention)Java进程消耗CPU过高等。此时我们需要利用一些命令来分析问题所在。
- jstack: jstack主要用来查看某个Java进程内的线程堆栈信息。
- jstack [option] pid
- jstack [option] executable core
- jstack [option] [server-id@]remote-hostname-or-ip
- -l : long listings,会打印出额外的锁信息,在发生死锁时可以用jstack -l pid来观察锁持有情况
- -m : mixed mode,不仅会输出Java堆栈信息,还会输出C/C++堆栈信息(比如Native方法)
jmap(Memory Map)/jhat(Java Heap Analysis Tool):jmap用来查看堆内存使用状况,一般结合jhat使用。如果运行在64位JVM上,可能需要指定-J-d64命令选项参数。
- jmap [option] pid
- jmap [option] executable core
- jmap [option] [server-id@]remote-hostname-or-ip
jstat:JVM统计监测工具
- jstat [ generalOption | outputOptions vmid [interval[s|ms] [count]] ]
- vmid是虚拟机ID,在Linux/Unix系统上一般就是进程ID。interval是采样时间间隔。count是采样数目。比如下面输出的是GC信息,采样时间间隔为250ms,采样数为4:jstat -gc 21711 250 4
- jstat [ generalOption | outputOptions vmid [interval[s|ms] [count]] ]
- jps(Java Virtual Machine Process Status Tool):jps主要用来输出JVM中运行的进程状态信息。
jps [options] [hostid]
- hostid:如果不指定hostid就默认为当前主机或服务器。
- options:
- -q : 不输出类名、Jar名和传入main方法的参数
- -m : 输出传入main方法的参数
- -l : 输出main类或Jar的全限名
- -v : 输出传入JVM的参数
VisualVM
这是一个Java程序性能分析工具
Tomcat调优参数
- maxThreads :Tomcat 使用线程来处理接收的每个请求,这个值表示 Tomcat 可创建的最大的线程数,默认值是 200
- minSpareThreads:最小空闲线程数,Tomcat 启动时的初始化的线程数,表示即使没有人使用也开这么多空线程等待,默认值是 10。
maxSpareThreads:最大备用线程数,一旦创建的线程超过这个值,Tomcat 就会关闭不再需要的 socket 线程。
上边配置的参数,最大线程 500(一般服务器足以),要根据自己的实际情况合理设置,设置越大会耗费内存和 CPU,因为 CPU 疲于线程上下文切换,没有精力提供请求服务了,最小空闲线程数 20,线程最大空闲时间 60 秒,当然允许的最大线程连接数还受制于操作系统的内核参数设置,设置多大要根据自己的需求与环境。当然线程可以配置在“tomcatThreadPool”中,也可以直接配置在“Connector”中,但不可以重复配置。
URIEncoding:指定 Tomcat 容器的 URL 编码格式,语言编码格式这块倒不如其它 WEB 服务器软件配置方便,需要分别指定。
- connnectionTimeout: 网络连接超时,单位:毫秒,设置为 0 表示永不超时,这样设置有隐患的。通常可设置为 30000 毫秒,可根据检测实际情况,适当修改。
- enableLookups: 是否反查域名,以返回远程主机的主机名,取值为:true 或 false,如果设置为false,则直接返回IP地址,为了提高处理能力,应设置为 false。
- disableUploadTimeout:上传时是否使用超时机制。
- connectionUploadTimeout:上传超时时间,毕竟文件上传可能需要消耗更多的时间,这个根据你自己的业务需要自己调,以使Servlet有较长的时间来完成它的执行,需要与上一个参数一起配合使用才会生效。
- acceptCount:指定当所有可以使用的处理请求的线程数都被使用时,可传入连接请求的最大队列长度,超过这个数的请求将不予处理,默认为100个。
- keepAliveTimeout:长连接最大保持时间(毫秒),表示在下次请求过来之前,Tomcat 保持该连接多久,默认是使用 connectionTimeout 时间,-1 为不限制超时。
- maxKeepAliveRequests:表示在服务器关闭之前,该连接最大支持的请求数。超过该请求数的连接也将被关闭,1表示禁用,-1表示不限制个数,默认100个,一般设置在100~200之间。
- compression:是否对响应的数据进行 GZIP 压缩,off:表示禁止压缩;on:表示允许压缩(文本将被压缩)、force:表示所有情况下都进行压缩,默认值为off,压缩数据后可以有效的减少页面的大小,一般可以减小1/3左右,节省带宽。
- compressionMinSize:表示压缩响应的最小值,只有当响应报文大小大于这个值的时候才会对报文进行压缩,如果开启了压缩功能,默认值就是2048。
- compressableMimeType:压缩类型,指定对哪些类型的文件进行数据压缩。
- noCompressionUserAgents=”gozilla, traviata”: 对于gozilla, traviata浏览器,不启用压缩。
如果已经对代码进行了动静分离,静态页面和图片等数据就不需要 Tomcat 处理了,那么也就不需要配置在 Tomcat 中配置压缩了。
以上是一些常用的配置参数属性,当然还有好多其它的参数设置,还可以继续深入的优化,HTTP Connector 与 AJP Connector 的参数属性值,可以参考官方文档的详细说明:
Tomcat7:HTTP Connector
Tomcat7:AJP Connector
引用
Tomcat 调优及 JVM 参数优化
Java 8: 从永久代(PermGen)到元空间(Metaspace)
《垃圾回收的算法与实现》——分代垃圾回收
GC详解及Minor GC和Full GC触发条件总结
GC是如何判断一个对象为”垃圾”的?被GC判断为”垃圾”的对象一定会被回收吗?
RednaxelaFX关于GC的回答
深入理解 Java G1 垃圾收集器
Java垃圾回收机制
引用计数算法
标记-清除算法
标记-压缩算法
半区复制算法
Java垃圾回收机制
JVM性能调优监控工具jps、jstack、jmap、jhat、jstat使用详解
JVM内存区域划分(JDK6/7/8中的变化)
Java中的四种引用方式的区别
Java 7之基础 - 强引用、弱引用、软引用、虚引用