HBase特点
HBase是一个分布式、列式存储、稀疏(HBase的列值为null可以不占用空间)的key-value数据库。
- 线性、模块化的可扩展性
- 读写强一致性(HBase是CP系统)
- 表可自动或手动配置分片
- RegionServers之间的自动故障切换支持
- HBase Tables可以很好地支持MR作业
- Java API Client简单易用
- Block cache 和 Bloom Filters用于实时查询
- Thrift网关和支持XML,Protobuf和二进制数据编码的RESTful Webservice
- 可扩展的 jruby-based (JIRB) shell
- Support for exporting metrics via the Hadoop metrics subsystem to files or Ganglia; or via JMX
HBase Shell
比起HBase shell我个人更加愿意用Web写GUI来替代Shell。
基本概念
- rowkey:rowkey便是HBase Table的索引。
- 散列:常用时间倒序,加盐散列等
- 预分区:相当于手工设定负载均衡
- rowkey一般根据业务设定,唯一性,字典ASCII排序
- Column Family:存储在HDFS上的一个单独文件中,列的空值不会被保存。
- Column
- Version Number:类型为Long,默认值是系统时间戳,可由用户自定义
- Value(Cell):Byte array
- Region:Region是RegionServers负载均衡的最小单元,表按行分片得到Region。Region可自动分裂,也可以预分区。
- Table
在一个HBase Table中:
- 表是行的集合
- 行是列族的集合
- 列族是列的集合
- 列是键值对的集合
下图可以是一个稀疏矩阵,且为null的列不会占用空间。注意:HBase的列不属于建表的元数据,这才使得列为null可以不占用存储空间,但代价是每个Cell都需要包含列的具体信息,还有版本号之类的其他信息。
HBase架构
HBase架构图

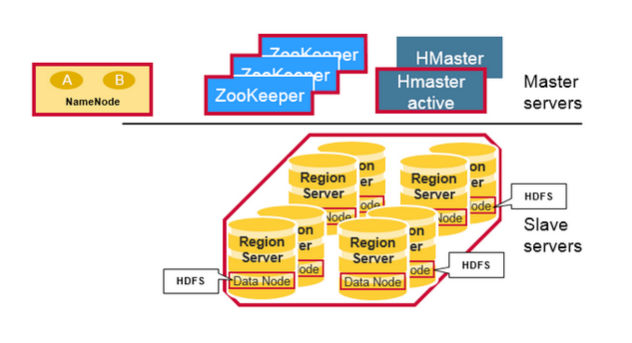
HBase是Master-Slave集群架构。
HBase由HMaster节点、HRegionServer节点、ZooKeeper集群节点组成,而底层存储则基于HDFS。
HBase Client通过RPC方式和HMaster、HRegionServer通信;一个HRegionServer可以存放X个HRegion;底层Table数据存储于HDFS中,而HRegion所处理的数据尽量和数据所在的DataNode在一起,实现数据的本地化;数据本地化并不是总能实现,比如在HRegion移动(如因Split)时,需要等下一次Compact才能继续回到本地化。
- HMaster
- 管理HRegionServer,实现其负载均衡。
- 管理和分配HRegion,比如在HRegion split时分配新的HRegion;在HRegionServer退出时迁移其内的HRegion到其他HRegionServer上。
- 实现DDL操作(Data Definition Language,namespace和table的增删改,column familiy的增删改等)。
- 管理namespace和table的元数据(实际存储在HDFS上)。
- 权限控制(ACL)。
- HRegionServer
- 存放和管理本地HRegion。
- 读写HDFS,管理Table中的数据。
- Client直接通过HRegionServer读写数据(从HMaster中获取元数据,找到RowKey所在的HRegion/HRegionServer后)。
- ZooKeeper集群是协调系统
- 存放整个 HBase集群的元数据以及集群的状态信息。
- 实现HMaster主从节点的failover。(主从故障自动切换)
HRegionServer(RegionServer)
HRegion(即Region)
HBase使用RowKey将表水平切割成多个HRegion,从HMaster的角度,每个HRegion都纪录了它的StartKey和EndKey(第一个HRegion的StartKey为空,最后一个HRegion的EndKey为空),由于RowKey是排序的,因而Client可以通过HMaster快速的定位每个RowKey在哪个HRegion中(BloomFilter)。HRegion由HMaster分配到相应的HRegionServer中,然后由HRegionServer负责HRegion的启动和管理,和Client的通信,负责数据的读(使用HDFS)。每个HRegionServer可以同时管理1000个左右的HRegion(这个数字怎么来的?没有从代码中看到限制,难道是出于经验?超过1000个会引起性能问题?来回答这个问题:感觉这个1000的数字是从BigTable的论文中来的(5 Implementation节):Each tablet server manages a set of tablets(typically we have somewhere between ten to a thousand tablets per tablet server))。
- RegionServers负载Region
HBase的Table按行分片(分区)为Region,每个Region属于一个RegionServers。每个RegionServers管理着多个Region。
RegionServer是HBase的数据服务进程。负责处理用户数据的读写请求。
由这个图就可以了解到rowkey为何要散列,因为散列后rowkey落在不同的Region,才能在不同的RegionServer负载均衡。
并且Region可以在RegionServer之间发生转移。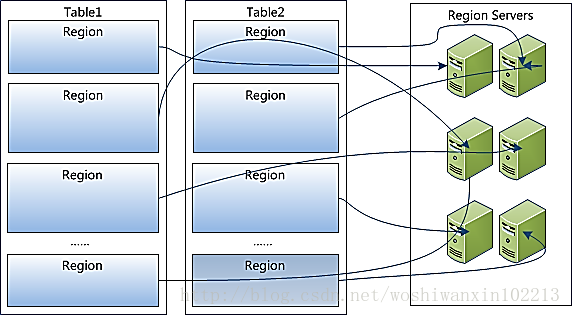
再看此图:Table被水平(按行)切分为Region,其依据便是Rowkey。属于一种RangePartitioner。每个Region都有一个StartRowkey和EndRowkey。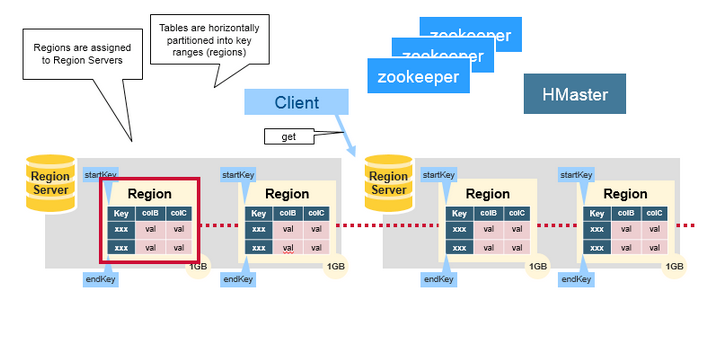
- 元数据Region(Meta Region)
Meta Region记录了每一个UserRegion的路由信息。
Client读写Region数据的路由:- 找寻Meta Region地址。
- 再由Meta Region找寻UserRegion地址。
- 用户Region(User Region)
HMaster
HMaster没有单点故障问题,可以启动多个HMaster,通过ZooKeeper的Master Election机制保证同时只有一个HMaster出于Active状态,其他的HMaster则处于热备份状态。一般情况下会启动两个HMaster,非Active的HMaster会定期的和Active HMaster通信以获取其最新状态,从而保证它是实时更新的,因而如果启动了多个HMaster反而增加了Active HMaster的负担。前文已经介绍过了HMaster的主要用于HRegion的分配和管理,DDL(Data Definition Language,既Table的新建、删除、修改等)的实现等,既它主要有两方面的职责:
- 协调HRegionServer
- 启动时HRegion的分配,以及负载均衡和修复时HRegion的重新分配。
- 监控集群中所有HRegionServer的状态(通过Heartbeat和监听ZooKeeper中的状态)。
- Admin职能
- 创建、删除、修改Table的定义。
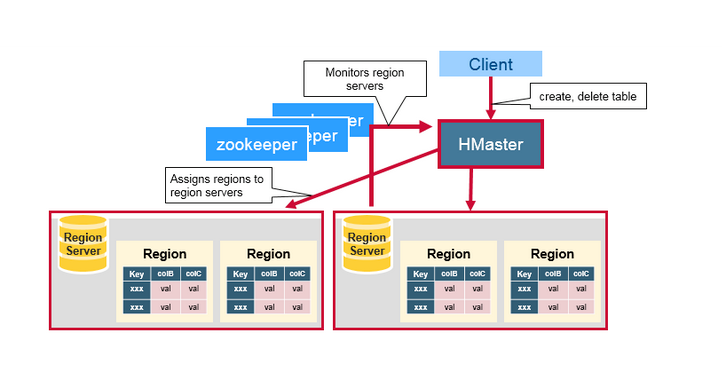
- 创建、删除、修改Table的定义。
ZooKeeper:协调者
ZooKeeper为HBase集群提供协调服务,它管理着HMaster和HRegionServer的状态(available/alive等),并且会在它们宕机时通知给HMaster,从而HMaster可以实现HMaster之间的failover,或对宕机的HRegionServer中的HRegion集合的修复(将它们分配给其他的HRegionServer)。ZooKeeper集群本身使用分布式一致性协议(PAXOS协议)保证每个节点状态的一致性。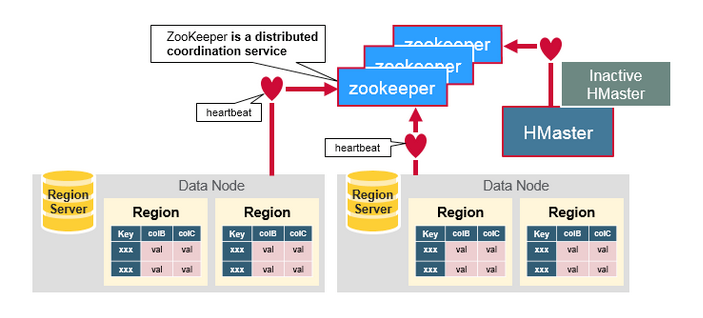
How The Components Work Together
RegionServers和Active HMaster通过Zookeeper的session相互联系。Zookeeper通过心跳维持临时ZNode(Ephemeral Node)的活动session。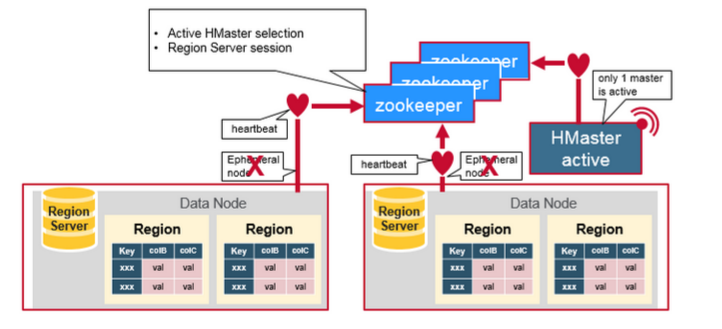
每个RegionServer都会创建一个临时ZNode,HMaster监视这些ZNodes来发现可用的RegionServer,同时也监控这些ZNode来判断RegionServer的健康状态。
HMasters也会竞争创建Ephemeral Node。Zookeeper选择第一个创建的HMaster作为Active HMaster。
Active HMaster会发送心跳给Zookeeper,而Inactive HMaster(非活动HMaster)会随时监听Active HMaster的故障。
如果Active HMaster或者Region Server无法发送心跳,则Zookeeper维护的session就会过期,相应的Ephemeral Node也会被删除。Znode被删除会通知订阅者Active HMaster/Inactive HMaster。
Region Server故障:Active HMaster会尝试去恢复Region Server;
Active HMaster故障:Inactive HMaster会尝试成为Active HMaster。
Compaction
在JVM中运行Java程序,随着Java程序的运行,越来越多的对象写入JVM,然后JVM需要根据实际情况(具体看:Tomcat调优、JVM调优与垃圾回收)触发GC,释放内存,且GC也分为Minor和Major两个类型(主要是Young GC和Full GC,也有说Minor GC和Major GC的)。
HBase的Compaction类似于JVM的GC,分为Minor Compaction和Major Compaction。
参考本文的HBase Region Flush章节,可以了解到MemStore的文件达到阈值后会flush到磁盘,表现形式是一个HFile文件。
随着程序的运行,HFile必然会越来越多。从而导致读数据时磁盘IO次数过多(寻址时间),影响效率。
Compaction操作是将将原来的HFile rewrite进新的HFile,所以Compaction期间会有大量的磁盘IO。
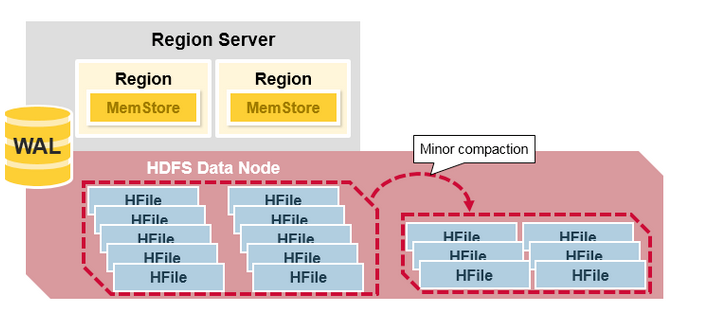
Minor Compaction
HBase的Minor Compaction会自动选择一部分较小的、相邻的HFile合并成较大的HFile。在此过程只做合并操作而不做删除操作,即处理minVersion=0并且设置TTL的过期版本清理,不处理被Delete和版本已过期的Cell(这些数据本应在物理层面被删除)。
如图所示:Minor Compaction将一个Region Server下的所有HFile合并成更少数量更大的HFile。
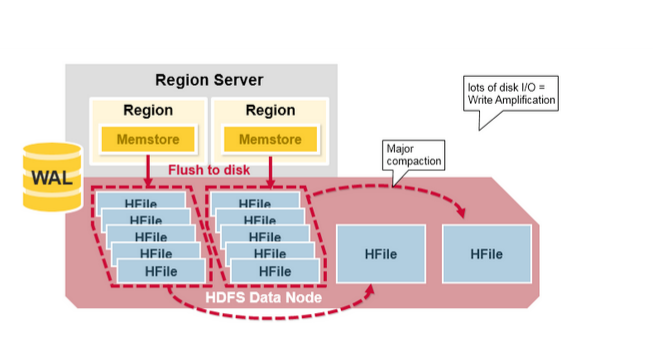
Major Compaction
如图所示:针对不同的列族,Major Compaction merge并rewrite一个region 下的所有HFIle为一个更大的HFile。
在此过程,清除一下数据:
被删除的数据deleted cells
TTL过期数据 expired cells.
版本号超过设定版本号的数据。
Major Compaction会带来大量的磁盘IO,严重影响性能。所以一般是设定在闲时执行,或者手动执行。
HBase第一次读/写流程
HBase有一个特别的元数据表.META.。META Table存储了HBase集群的所有Regions的位置。
而Zookeeper则保存了META Table的位置。
所以HBase第一次读流程如下:
- Client通过Zookeeper获取META Table的Region Servers
- Client查询META Table,根据rowkey定位到相应的Region Server
- Client从Region Server读取到/写入数据
而对于之后的读操作,Client会通过缓存定位META Table,和先前缓存的rowkey。
随着时间推移,Client不需要再查询META Table,除非由于Region移动导致缓存无法命中。此时便会重新查询并更新缓存。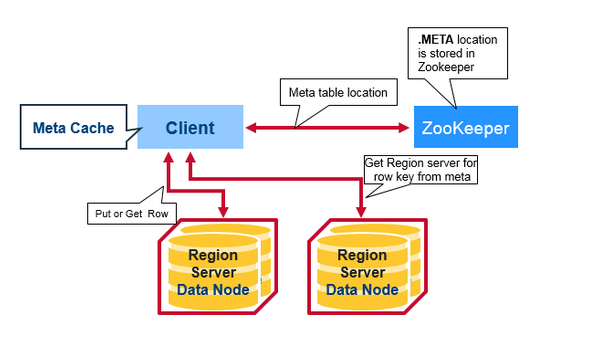
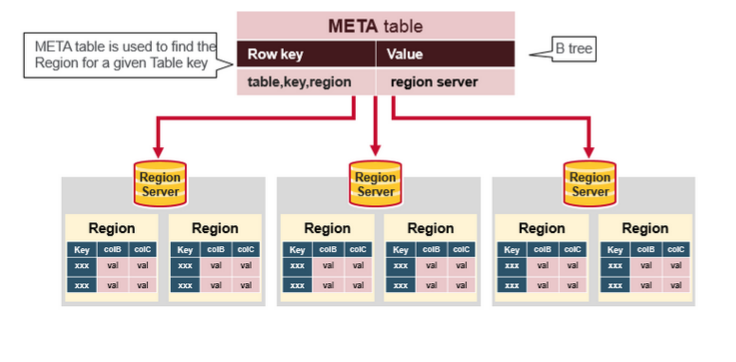
HBase META Table(.META.)
- META Table是一个HBase的表,存储了HBase集群的Regions元数据
- META Table类似与B-Tree(B-Tree又叫平衡多路查找树,常用于数据库索引)
- META Table结构如下:
- Key:region start key,region id
- Values:RegionServer
Region Server的组件
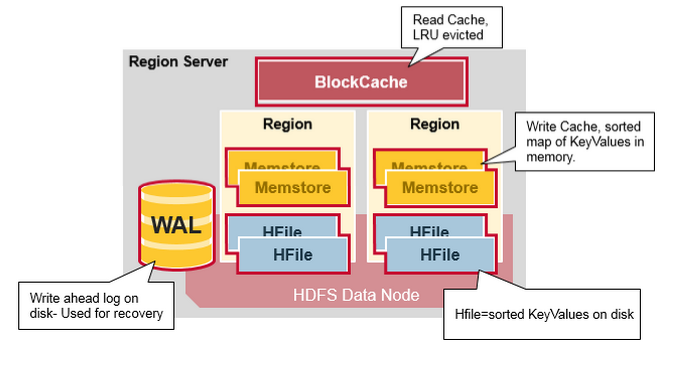
RegionServer运行在HDFS的DataNode上。包含以下组件:
- WAL:Write Ahead Log(HLog)也是分布式文件系统的一个文件,每个RegionServer共享一个HLog。类似与MySQL的binlog,用于存储HBase的数据变更操作记录。用于HBase故障时的数据恢复。
- BlockCache:读缓存。HBase在内存中存储了频繁读取的数据,缓存淘汰算法是 Least Recently Used,LRU.
MemStore:写缓存,用于缓存那些写入了WAL但是还没写入磁盘的数据。
HBase Table横向切分为Region,纵向切分为列族。HBase是列式数据库,所以列族是已一个HStore存储在HDFS上。
还有一点,假设列族存在数据倾斜,每个列族包含的数据量差异巨大。当Region根据rowkey横向分裂,造成列族数据不均匀分布。
这就要求我们在设计HBase的表时,具有相同IO特性的列应该归于同一个列族,避免由于跨列族访问而导致的跨物理存储访问数据。
HStore包含1个MemStore和多个StoreFile(HFile)。
HBase每个列族的每个Region的每个Store包含一个MemStore和多个StoreFile(HFile),详细可看架构图。
具体我总结出一个HBase Table的物理存储和抽象映射图,具体如下: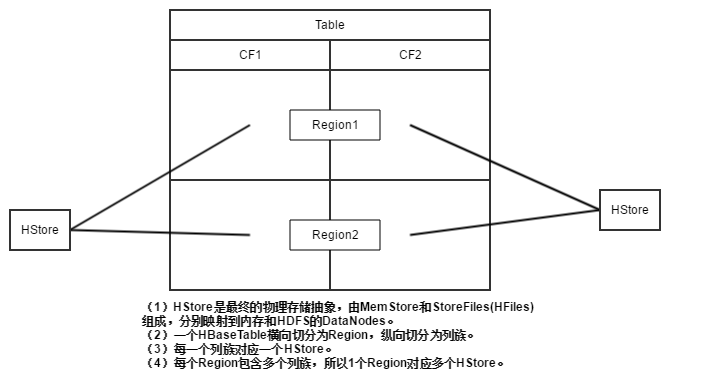
HFiles:基于HDFS,在磁盘上存储了有序的KeyValues。
HBase MemStore
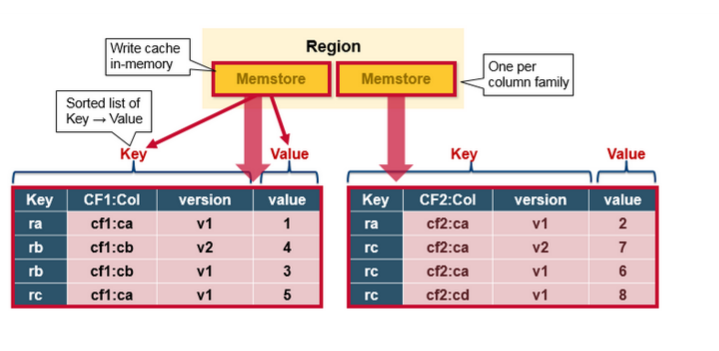
HBase读写流程
图中读流程,缺少BlockCache的描述。
rowkey检索流程
- 访问Zookeeper定位META Table的Region位置
- 访问META Table定位rowkey对应的Region位置
- PS:之后会通过缓存提高定位效率。
写流程
- 检索rowkey
Client的Put请求,首先写WAL:
- Edits会被追加在WAL的末尾(写入磁盘)
- 当HBase故障时,WAL用于恢复未持久化的数据
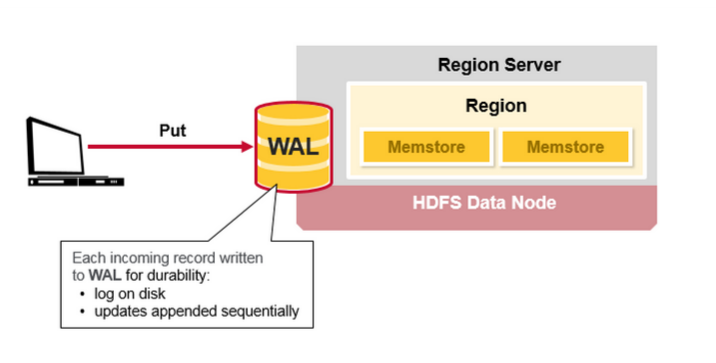
Client写入WAL后,会写入MemStore,之后直接告诉客户端写入成功(这样保证了高效的写性能)
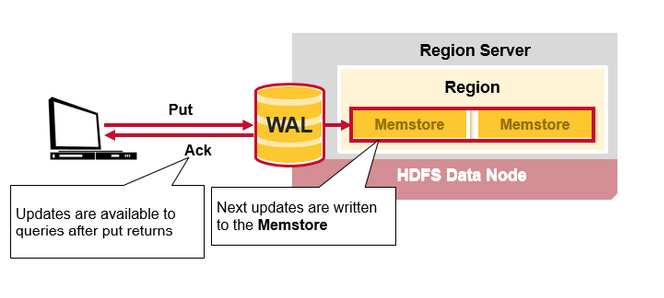
读流程
- 检索rowkey
- 读BlockCache
- 读MemStore
- 读HFile
- PS:在任意地方(BlockCache,MemStore,HFile)读到都返回结果,这里通过ReadPoint、WriteNumber实现读写一致性的事务。
HBase Region Flush
MemStore存储达到阈值,那么位于MemStore的有序数据集就会写入一个新的HFile。这个过程称之为Flush。
每个列族会有多个HFiles,HFile基于HDFS,存放着HBase的实际数据。
这里引出一个问题:HBase的列族数量为什么不应过多?
MapR解析:There is one MemStore per CF; (和上面的There is one MemStore per column family per region.岂不是矛盾,或者表达的是one of the MemStore of CF?)when one is full, they all flush. It also saves the last written sequence number so the system knows what was persisted so far.
意思就是1个MemStore的flush会触发其所在Region内(等价于所在Table)的所有MemStore的flush,所以列族越多,就会有越多的flush,频繁的IO便会影响性能。
flush过程包括:(其实和HDFS的NameNode的edit log的flush(checkpoint)流程是非常相似的,就是swap的思路)
- 触发时机:某个Region内的一个MemStore达到阈值,触发整个Region内的所有MemStore的flush操作。
prepare(基于MemStore做snapshot)
遍历Region的所有MemStore,将MemStore的数据保存为snapshot,然后新建一个MemStore.NEW,新的写入操作会将数据写入MemStore.NEW。
flush时,读请求会先从MemStore和MemStore.NEW读取操作,缓存位命中,才会去访问HFile。
就在生成快照的时候,会上updateLock,阻塞写请求。flushcache(基于snapshot生成临时文件)
遍历所有snapshot,将snapshot持久化为临时文件,目录是.tmp。这里涉及到磁盘IO,耗时操作。
commit(确认flush操作完成,rename临时文件为正式文件名称,清除mem中的snapshot)
遍历所有的Memstore,将flush阶段生成的临时文件移到指定的ColumnFamily目录下,针对HFile生成对应的storefile和Reader,把storefile添加到HStore的storefiles列表中,最后再清空prepare阶段生成的snapshot。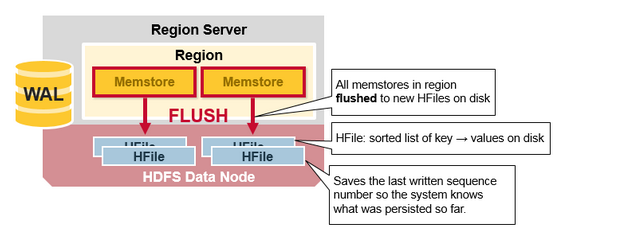
HBase的ACID
ACID是指原子性(Atomicity),一致性(Consistency),隔离性(Isolation)和持久性(Durability)
- 原子性(Atomicity):整个事务中的所有操作,要么全部完成,要么全部不完成,不可能存在中间状态。
- 一致性(Consistency):事务提交后,所有读操作都可以读到事务提交后的一致的数据。
- 隔离性(Isolation):并发事务之间相互隔离,互不影响。
- 持久性(Durability):在事务提交后,该事务对数据库所作的更改便持久的保存在存储介质之中,并且不可变。
在HBase里面,提供有限度的ACID特性: - 原子性:行级锁,保证行更改时的原子行,对某一行的更改操作要么全部成功,要么全部失败。
- 一致性:1行数据存在于Region,而Region属于1个RegionServer。该行数据更新后,所有读操作都会定位到此Region读取唯一的最新的数据。所以数据一致。
- 隔离性:行与行的事务互不影响,同行事务由于“写行”操作的原子性,那么并发写必然是串行的,也必然是隔离的。
- 持久性:事务一旦提交,WAL数据便认为不可破坏。即使宕机导致MemStore数据丢失,从WAL也能恢复数据。
- HBase写时流程:
- 锁行,相同行无法并发写操作
- 获取WriteNumber(相当于事务版本号)
- 写WAL
- 写MemStore
- 更新ReadPoint为最新的WriteNumber
- 释放锁
- HBase读时流程:
- 打开Scanner
- 获取最新ReadPoint
- 顺序读取BlockCache、MemStore、HFile,直至取得数据
- 关闭Scanner
HBase的锁[TODO:存疑]
行锁RowLock
用于实现“写行”时的原子性。RowLock有Lease租约的机制,超时会自动释放行锁。(即使是超时释放行锁,整个操作也是要么全部成功,要么全部失败,保持原子性)
MVCC:Multi-Version Concurrency Control 多版本并发控制
参考HBase读写流程的WriteNumber和ReadPoint,读写版本分离。
MemStore锁
对Store的写操作会调用Memstore的相关操作,在对memstore做snapshot以及清除snapshot的时候会阻塞其他操作(如add、delete、getNextRow)。
Region锁
在做更新操作时,需要判断资源是否满足要求,如果到达临界点,则申请进行flush操作,等待直到资源满足要求(参见Region中的checkResource)
Region update更新锁(updatesLock),在internalFlushCache时加写锁,导致在做Put、delete、increment操作时候阻塞(这些操作加的是读锁)。
Region close保护锁(lock),在Region close或者split操作的时(加写锁),阻塞对region的其他操作(加读锁),比如compact、flush、scan和其他写操作。
StoreFile锁
其中在flush过程的commit阶段,compact过程的completeCompaction阶段(rename临时compact文件名、清理旧的文件),close store(关闭store),bulkLoadHFile,会阻塞对store的写操作。
协处理器Coprocessor
Observer(类似触发器)
EndPoint(类似与存储过程)
二级索引
Coprocessor Observer实时同步构建
写队列异步构建
ETL(MapReduce/Spark/DataX等)批量离线构建
引用
深入HBase架构解析(一)
深入HBase架构解析(二)
An In-Depth Look at the HBase Architecture
Hbase原理、基本概念、基本架构
Apache HBase Internals: Locking and Multiversion Concurrency Control
总结一下HBase各种级别的锁以及对读写的阻塞
Configuring HBase Memstore: What You Should Know
HBase – Memstore Flush深度解析