Storm基本原理与概念
Component
组件,Spout和Bolt都是组件,从代码上看Spout和Bolt都是实现了IComponent接口的。
Topology 拓扑
Storm实时流式计算的逻辑封装便是封装在拓扑中,在分布式环境中组成拓扑的成员便是Component,即Spout和Bolt。
Storm和MapReduce很是相似,MR总会执行完毕,而Storm会一直在后台运行,监听数据源的输入。
个人认为拓扑也应是一个有向无环图(DAG)。
拓扑图: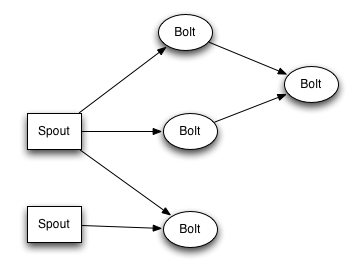

Stream 数据流
数据流Stream是Storm数据流动的一个抽象概念。
数据流是一个无界Tuple序列,Stream是分布式、并行地被处理和创建的。
数据流在创建元组Tuple的时候,通过定义Schema来声明的。在declareOutputFields使用declare.declareStream方法定义Stream。
定义Schema主要是确定streamId,如果不声明streamId,那么数据流默认的streamId是default。
streamId的作用是:在定义拓扑的时候,分组策略可以通过指定streamId来限定Storm算子只处理来自指定数据流的数据。且每个Bolt只支持订阅1个Stream。
- Component(Spout/Bolt)可以发射多个数据流stream,通过多次调用
declareStream声明多个streamId。
Spout
- Spout通常负责从外部读取数据,并处理成Tuple分发到拓扑中。
- Spout可以是可靠的,也可以是不可靠的:
- 可靠Spout:如果Tuple处理Tuple失败,Spout可以重新处理;
- 不可靠Spout:Spout一旦emit了元组,便不管该元组是否能被成功处理。
- Spout中的主要方法是:
nextTuple:nextTuple负责向拓扑发射元组,如果没有元组,则需要直接返回,有时为了避免消耗过度的CPU资源,没有元组时可能sleep较短时间,比如1ms。
需要特别注意,nextTuple是绝对不能是一个阻塞方法,因为Storm会调用同一个线程的所有spout的实现,如果阻塞了某个Spout线程,会影响Spout的并行处理速度。ack和fail:在可靠Spout中,当emit Tuple失败或者成功时,会调用他们来告诉storm处理结果。下游Component处理上游Component emit 过来的Tuple,调用OutputCollector.ack(input)或者OutputCollector.fail(input)nextTuple、ack和fail会在同一个线程被调用。PS:听说JStorm已经是异步调用ack和fail了。
Bolt
几乎所有的Storm计算都是通过Bolt来完成的,包括:filtering过滤, functions函数, aggregations聚合, joins连接, talking to databases操作数据库等等。
- 通过使用提供的TopologyContext或通过跟踪OutputCollector中的emit方法的输出(返回发送元组的任务ID),消费者的任务ID。
- Bolt中的主要方法是:
execute:execute负责接收上游组件发射来的Tuple,然后将输入的Tuple转换成新的Tuple发射出去。调用方法:OutputCollector.emit(newTuple)。OutputCollector是线程安全的,所以在execute中可以使用多线程来异步处理Tuple来进行emit操作。BasicBoltExecutor implements IRichBolt使用装饰者模式(他们共同的接口是IComponent),对于实现了IBasicBolt的bolt会自动执行ack操作。
Stream grouping 流分组策略
下游Bolt通过调用相关的Grouping方法来订阅上游Component的输出数据(Tuple)来作为自己的输入。
- Shuffle grouping(随机分组):元组随机分布在Bolt的Tasks中,每个Bolt都能得到一样数量的Tuples。
- Fields grouping(域分组):上游数据流由Fileds进行分区,下游Bolt通过订阅上游Component指定的Fileds获取数据,每个Bolt只能接收它订阅了的Fields。
- Partial grouping(部分关键字分组):和Fields grouping类似,在数据倾斜的情况下,能更好地实现负载均衡。原理见此处
- All grouping(完全分组):广播分组,每个Tuple都会emit到每一个Bolt中去
- Global grouping(全局分组):全部Tuple都会emit到一个Bolt的一个Task中去
- None grouping(非分组):不关心数据流是否被分组,目前相当于Shuffle grouping,不过Storm会把使用None grouping的这个bolt放到它订阅的Spout/Bolt所在的同一个线程里面去执行(如果可能的话)。
Direct grouping(直接分组):上游Component指定下游Bolt的Task来接收Tuple。Direct grouping只能用于
direct streams,通过调用emitDirect将Tuples发射到direct streams,并指定taskId。一个上游Bolt(生产者)如何获得下游Bolt(消费者)的taskIds呢?
通过TopologyContext或者追踪OutputCollector.emit方法,Tuple发射成功后,会返回Tuples发送到的taskIds。Local or shuffle grouping(本地或随机分组):如果目标Bolt在同一个worker进程(指和生产者在同一个进程)有一个或多个Tasks,Tuples会被优先随机分发到进程内的Tasks(Local grouping)。否则边是shuffle grouping。
- CustomStreamGrouping:通过实现
CustomStreamGrouping接口来自定义分组策略。
数据流分组图: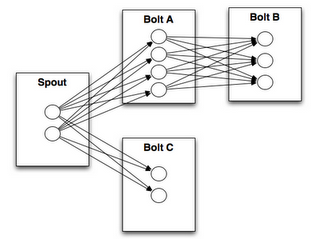
Partial grouping(部分关键字分组)
- processing elemen(PE):流处理应用程序组成DAG,DAG顶点就叫PE(算子)
- streams:DAG的边和运算符表示流
- processing element instance (PEI):为了可伸缩,streams会被分区为sub-streams,就会交由PEI进行并行处理
- key splitting:power of two choices(PoTC)当key做Hash或者其他分区方法进行分区,每个key可以被2个PEI处理(在Storm里应该就是2个Bolt),这个过程就叫key splitting。在Storm里面,会根据2个Bolt的负载进行均衡。
- Local Load Estimation:那如何进行负载的判断?好吧,看论文和源码去吧~
可靠性
Storm保证每个Spout Tuple会被完全处理。Storm通过追踪由每个Spout元组触发的元组树,并确定元组树何时完全完成。
元组树:第一个元组从Spout发出,之后在拓扑中流转分裂变形成更多的元组,这些元组构成了一棵树。第一个Spout Tuple便是树的根节点。
每个拓扑都有一个”message timeout(消息超时)”,如果Storm在超时时间内无法检测到Tuple是否已经被完全处理则会认为处理失败,
并且稍后的时间释放该元组(这儿的稍后是啥时候?如果此段时间存在大量Timeout Message会不会造成OOM?会不会在内存满时触发清除超时元组?)。
元组树的“边”在被创建(Anchoring)和元组被处理完成(ack/fail)的时候,通过OutputCollector来通知Storm。Anchoring通过OutputCollector.emit完成,ack/fail通过OutputCollector.ack/OutputCollector.fail或BasicOutputCollector.emit(底层调用了OutputCollector.ack(input))完成。
详见此处:Guaranteeing Message Processing
如何去除可靠性
- Spout发射Tuples的时候不带上messageId,因为Storm的ack机制是通过msgId进行追踪的。
- 设置
Config.TOPOLOGY_ACKERS为0(即Config.setNumAckers(0)),这样子Spout会在发射一个Tuple后自己立刻调用ack方法。 - 使用
Unanchor方式发射元组:比如使用OutputCollector.emit发射元组,而BasicOutPutCollector.emit则是anchor的方式。BasicOutPutCollector.emit底层会自动构建Tuple,并通过调用OutputCollector.emit发射元组,所以是anchor的方式。
而直接调用OutputCollector.emit,底层不会构建Tuple,所以是Unanchor方式。
他们最底层的方法接口都是:IOutputCollector.emit(String streamId,Collection<Tuple> anchors,List<Object> tuple)
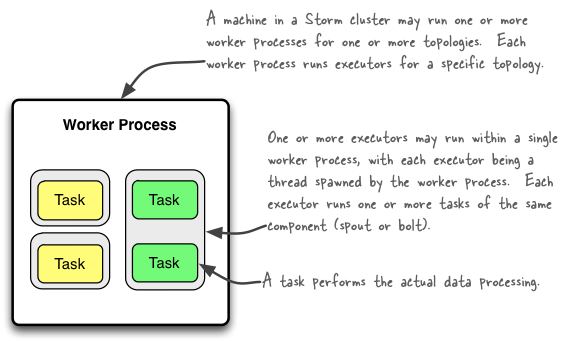
Task
每个Task对应的是一个线程,数据流分组决定了上游Tasks的元组如何流动到下游Tasks中。
Worker
指的是Worker进程,在这个JVM进程中,执行了一组Spout/Bolt的Tasks,每个Worker只能对应一个拓扑。
Executor
每个Worker进程中运行了一个或多个Executor线程。每个Executor可以执行一个或多个Task(不过一般设置为1Executor:1Task),
每个Executor只对应一个Component(Spout/Bolt)
PS:以上三者可以通过下图来描述: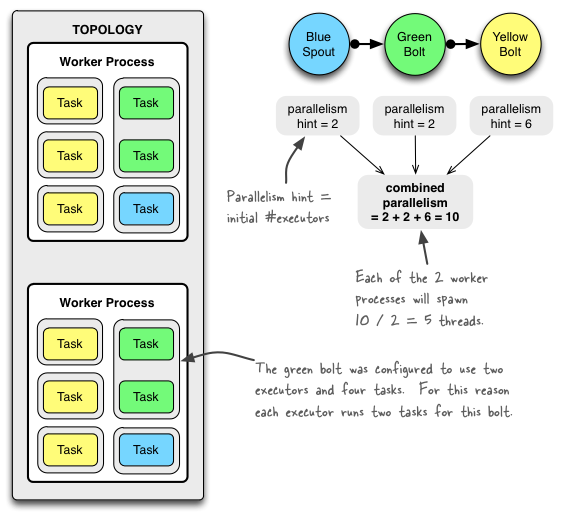
parallelismHint(并行度)
- Worker并行度:
Config.TOPOLOGY_WORKERS,通过Config.setNumWorkers设定,表示Storm在集群中会启动多少个Worker进程来处理此拓扑。 - Component并行度:在调用
TopologyBuilder.setSpout和TopologyBuilder.setBolt的时候,可传入并行度参数,并行度参数确定了一个Component(Spout/Bolt)的初始 executor (线程)数量。 Task并行度:
Config.TOPOLOGY_MEX_TASK_PARALLELISM,通过Config.setMaxTaskParaellelism设定,表示一个Component在拓扑中的最大并行任务(此参数常用来限制在本地模式中的最大线程数)。- 通过
TopologyBuilder.setSpout.setNumTasks和TopologyBuilder.setBolt.setNumTasks可以设置一个Component的Executor中运行的Task数量
这里列举的都是通过代码配置参数,配置优先级:defaults.yaml < storm.yaml < topology-specific configuration < internal component-specific configuration < external component-specific configuration
Nimbus
Storm也是Master-Slave模式,和Spark,HDFS,HBase等Hadoop组件的设计是一样的。且整个Storm Cluster是无状态的,所有状态都维护在zookeeper中。
Nimbus便是Storm在Master节点的守护进程,Storm Client将拓扑提交到Nimbus,Nimbus将拓扑相关代码分发到负责Slave节点(工作节点),Slave节点的Supervisor守护进程会生成Worker执行Spout/Bolt的Task。
Nimbus还会监控Slave的状态。因为Supervisor的状态会记录在zookeeper,Nimbus通过zk得知Supervisor是否健康。
如果Supervisor挂了,Nimbus会将它的Task分配给其他节点。
Supervisor
Supervisor是Storm在Slave节点(工作节点)的守护进程,负责监听Slave节点上由Master分配的Task,并启动合适数量的Worker。
Supervisor也会监控Worker进程的状态,如果Worker挂了,Supervisor会重新启动新的工作进程(Worker Process)。
Nimbus、Supervisor与zookeeper关系如图: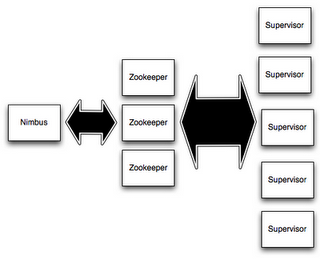
Nimbus HA (Since Storm 1.x)
Tuple 元组
元组默认支持integers, longs, shorts, bytes, strings, doubles, floats, booleans, and byte arrays.
用户可以通过实现自己的序列化器使得Tuple可以支持自定义对象类型。
Field
通过OutputFieldsDeclarer.declare来定义Fields,new Values(col1,col2)与new Fields(field1,field2)顺序对应。
BasicBoltExecutor与BaseBasicBolt
自动调用ack,一开始以为是模板方法。后来看了BasicBoltExecutor发现是装饰者,这儿有点意思。
对于可靠的消息处理,若希望自动ack,理应继承BaseBasicBolt而不是BasicRichBolt。BasicBoltExecutor对于Tuple会自动ack,并且ack失败会自动调用fail方法重发。
Storm与MapReduce
我写Spark的时候,MR类思想总感觉可以对应上Storm,遂搜寻有下表:来源
| MapReduce | Storm | |
|---|---|---|
| 系统角色 | JobTracker | Nimbus |
| 系统角色 | TaskTracker | Supervisor |
| 系统角色 | Child | Worker |
| 应用名称 | Job | Topology |
| 组件接口 | Mapper/Reducer | Spout/Bolt |
Storm消息保证等级
对于消息在集群中传递,比如Kafka,JMS等消息机制,都会有类似的保证机制等级。
- At Most Once: 最多一次,消息只发送一次,消息不重复、可丢失。即Tuple不进行Track。
- At Least Once: 至少一次,消息至少发送一次,消息不丢失、可重复。即Tuple被Track,失败了会进行重发,直至成功,所以可能会造成重复计算。
- Exactly Once: 恰好一次,消息只发送一次,消息不重复、不丢失。提供TridentAPI,实现事务Tuple。
Bolt的线程安全问题
No, they do not need to be thread-safe. Each task has their own instance of the bolt or spout object they’re executing,
and for any given task Storm calls all spout/bolt methods on a single thread.
Storm主程nathanmarz回答
既然如此,这里便有一个疑问:
Storm的Bolt的最小任务执行单元是Task,并且是Task是多实例的?
那么对于一些共享的资源,比如连接池,只能在在Task间共享?而不能在每个Executor甚至每个Worker共享?如果是这样子,岂不是作用域很小而导致资源浪费?
有人如果看到这个,希望可以解惑。
看到org.apache.storm.jdbc.bolt.AbstractJdbcBolt(JdbcInsertBolt)的源码,他的ConnectionProvider(HikariCPConnectionProvider)提供了连接池。也不过是Bolt上的一个实例域而已。