总体架构
Spark集群总体架构图如下: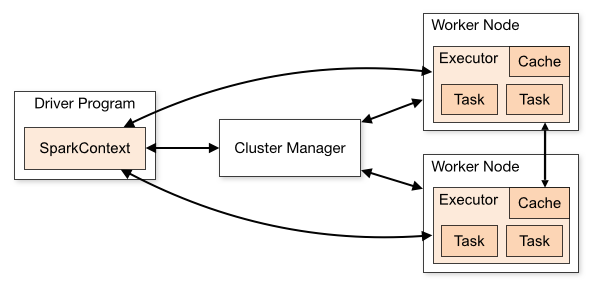
- Cluster Manager(集群管理器):
- Standalone – Spark自己的集群管理器
- Apache Mesos – 基于Mesos
- Hadoop YARN – 基于Yarn
这些集群管理器可以在应用间分配资源。SparkContext与Cluster Manager一旦连接,Spark需要在集群上的线程池子节点,也就是那些执行计算和存储应用数据的工作进程。然后,它将把你的应用代码(以JAR或者Python定义的文件并传送到SparkContext)发送到线程池。最后,SparkContext发送任务让线程池运行。
Application
指编写的Spark程序。
Driver
Spark作业的主进程,负责作业的解析,并且负责向yarn申请资源,并且调度作业的executor。
提交Spark Application到集群的时候,对于Spark来说,就是生成一个Driver进程来执行Spark App的main函数,并且初始化SparkContext。
DAGScheduler和TaskScheduler都是属于Driver的。
- Executor:执行器,里面包含了N个core,每个core包含了1个Task。
- DAGScheduler:负责生成Stage(DAG)和TaskSet,每个Stage就有一组TaskSet。
- TaskScheduler:接收DAGScheduler的TaskSet并发送给Executor。
疑问:为什么是有向无环图?
(1)有向图表示RDD可追溯,失败可以重运行。
(2)无环图表示RDD不可变,如果存在环,是否意味着RDD可变?
Job
可以认为在Spark App中,每一个Spark的Action API就是一个Job。
而Spark App可以有多个job,而Job可以划分成多个Stage,Stage是一组Task(即TaskSet):
Stage
Stage由Task组成,每个Stage内的Task是并行执行的,而Stage之间是串行的。
Stage的划分:每个Shuffle Dependency(即Wide Dependency)之前的所有RDD操作。
Task
Task有2类:ShuffleMapTask和ResultTask,类似与MapReduce的Map和Reduce。
Task的划分:Stage的最后1个RDD的分区数 = Task数量。
Task是并行的,合理设置分区可以提高资源利用率。
这些概念在Spark官网介绍如下
| Term | Meaning |
|---|---|
Application |
User program built on Spark. Consists of a driver program and executors on the cluster. |
Application jar |
A jar containing the user’s Spark application. In some cases users will want to create an “uber jar” containing their application along with its dependencies. The user’s jar should never include Hadoop or Spark libraries, however, these will be added at runtime. |
Driver program |
The process running the main() function of the application and creating the SparkContext |
Cluster manager |
An external service for acquiring resources on the cluster (e.g. standalone manager, Mesos, YARN) |
Deploy mode |
Distinguishes where the driver process runs. In “cluster” mode, the framework launches the driver inside of the cluster. In “client” mode, the submitter launches the driver outside of the cluster. |
Worker node |
Any node that can run application code in the cluster |
Executor |
A process launched for an application on a worker node, that runs tasks and keeps data in memory or disk storage across them. Each application has its own executors. |
Task |
A unit of work that will be sent to one executor |
Job |
A parallel computation consisting of multiple tasks that gets spawned in response to a Spark action (e.g. save, collect); you’ll see this term used in the driver’s logs. |
Stage |
Each job gets divided into smaller sets of tasks called stages that depend on each other (similar to the map and reduce stages in MapReduce); you’ll see this term used in the driver’s logs. |
RDD
RDD是Spark并行计算的基础。
RDD是一个只读的并行、可伸缩的分布式数据结构。
RDD由Partition组成。多个Partition可能被分配在不同的节点,但是1个Partition只能在一个节点(即对于一个分区来说,分区是不跨节点的)
分区是一个很关键的概念,具体可参考JDK的HashMap(哈希表的每个hash位置可以理解为1个分区)以及ConcurrentHashMap(每个桶理解为1个分区)源码,
类似的还有kafka的topic和Redis Cluster的slot概念。分区/分片,是弹性扩展数据结构的一个手段。
在Spark的RDD设计上,所有的窄依赖在分区上进行管道式的计算,以达到并行计算的目的。
如图:并行计算.png)
宽依赖与窄依赖
父RDD与子RDD的依赖关系:
(1)宽依赖:每个父RDD的任意Partition会被子RDD的多个Partition所依赖。发生了Shuffle的算子会产生Shuffle依赖
(2)窄依赖:每个父RDD的任意Partition只被子RDD的一个Partition所依赖。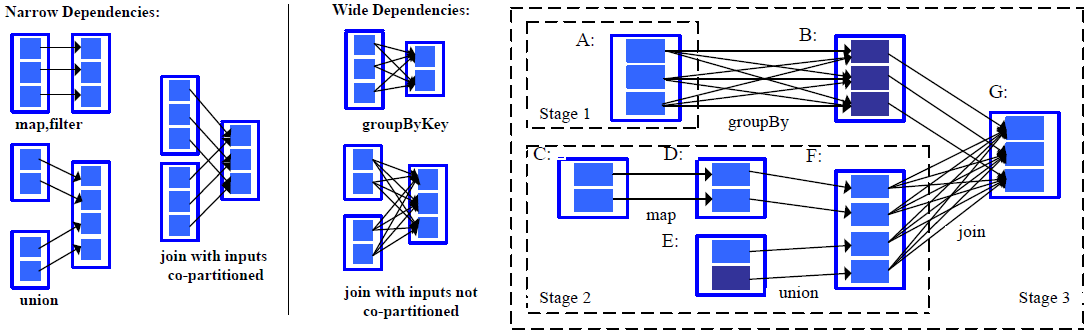
Spark为什么要区分宽依赖与窄依赖呢?
(1)窄依赖支持在同一个节点中,以pipeline(管道)的形式执行多条命令。
窄依赖计算是并行的、分区独立的(分区作为管道)。
而宽依赖在计算过程中会发生Shuffle,是跨分区的计算。
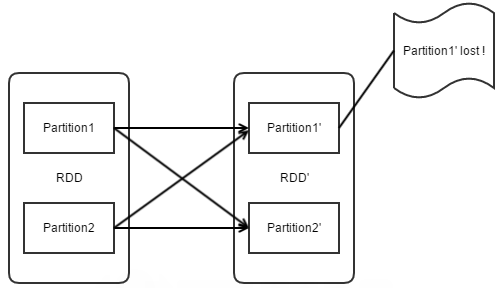
(2)从失败恢复的角度(容错机制)看:
窄依赖只需要重新计算丢失分区的父分区,而且不同节点之间可以并行计算。
宽依赖则需要重新计算子分区所依赖的所有父分区,并且产生冗余计算。
如下图:假设Partition1’丢失,则需要重新计算Partition1和Partition2,从而冗余计算了Partition2’。
宽依赖发生Shuffle的性能影响
- (1)Shuffle由于产生磁盘IO/网络IO/数据的序列化与反序列化会严重影响RDD算子的性能,Spark的Map Tasks生产Shuffle的数据,Reduce Tasks读取Shuffle数据来进行聚合操作。
注:Map Tasks和Reduce Tasks的命名法来自MapReduce,并不直接与Spark的Map和Reduce操作有关。 - (2)在Spark计算内部处理过程中,部分Map Tasks的计算结果会被缓存在内存里,直到内存不足才会被清理。然后,这部分数据会根据目标分区进行排序并写入单个文件。
而Reduce Task会去读取相关的排序块(sorted blocks)。 - (3)某些Shuffle操作会消耗大量的堆内存,因为它们在tranffer数据之前或之后会通过基于内存的数据结构来处理记录。具体来说,reduceByKey和aggregateByKey在Map端上创建这些基于内存的数据结构,
“ByKey”操作会在reduce端生成in-memory data structures。在内存不足的时候,Spark会将这些数据表溢写到磁盘,从而导致磁盘IO的额外开销和增加的垃圾回收。 - (4)Shuffle操作还会在磁盘上生成大量的中间文件。从Spark 1.3开始,这些文件将被保留,直到相应的RDD不再使用并被垃圾回收。这样的作用是如果需要重新计算Shuffled RDD,则不需要重新执行Shuffle过程。
如果Spark App保留对这些RDD的引用或不频繁触发GC,那么垃圾收集可能会在很长一段时间之后发生。这意味着Spark作业的产生的中间文件会长时间占用大量的磁盘。
在配置Spark上下文时,由spark.local.dir配置指定临时存储目录。
更多的Shuffle配置
RDD的持久化
| Storage Level | Meaning |
|---|---|
| MEMORY_ONLY | 默认模式,将RDD反序列化成Java对象存储在JVM内存,如果内存不足,某些分区不会被缓存,而是每次使用都重新计算。 |
| MEMORY_AND_DISK | 区别于MEMORY_ONLY,内存不足会写入磁盘,每次使用都从磁盘读取。 |
| MEMORY_ONLY_SER | 类似于MEMORY_ONLY,但存储对象的格式不一样,是将RDD序列化为字节数组(每个分区一个字节数组)。这通常比反序列化对象更具空间效率,特别是在使用快速序列化器如KryoSerializer的情况下,但却转化成CPU密集型作业(时间换空间)。 |
| MEMORY_AND_DISK_SER | 类似于MEMORY_ONLY_SER,内存不足会写入磁盘,每次使用都从磁盘读取。 |
| DISK_ONLY | RDD的partitions只被写入磁盘 |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2, etc. | 和上面的设置类似,不过会复制每个分区到2个集群节点上。 |
| OFF_HEAP (experimental) | 类似于MEMORY_ONLY_SER,但将数据存储在堆外内存中。这需要启用堆外内存。 |
RDD持久化选择
- 如果内存足够,使用默认存储级别(MEMORY_ONLY),速度最快并充分利用了CPU(会消耗大量内存)。
- 如果内存不足,使用MEMORY_ONLY_SER,通过消耗CPU将RDD序列化以节省空间(减少内存消耗)。
- 不要溢出到磁盘,除非并行计算资源成本过高,或者需要过滤大量的数据。否则,重新计算分区可能与从磁盘读取分区一样快。
- 如果要快速故障恢复,请使用
MEMORY_ONLY_2, MEMORY_AND_DISK_2, etc.(例如,使用Spark来提供来自Web应用程序的请求)。所有RDD持久化策略通过重新计算丢失的数据来提供完整的容错能力,但复制的数据可让您继续在RDD上运行任务,而无需重新计算丢失的分区。
缓存清除
Spark会自动监视每个节点的缓存使用情况,并以近期最少使用算法(LRU,Least Recently Used)方式丢弃旧的数据分区。 调用RDD.unpersist()可以手动清除缓存释放空间。
共享变量
通常,当提交到Spark操作(例如map或reduce)的函数在远程集群节点上执行时,在函数中使用的所有变量会生成副本到每个节点上,并且远程节点上变量的更新不会传播回Driver。
而在提供Task间共享的read-write shared variables是低效的。 不过Spark依然提供了两种有限类型的共享变量:广播变量broadcast variables和累加器accumulators。
广播变量
广播变量允许程序员在每个节点上缓存只读变量,而不是为每个Task生成变量副本。
使用情景举例:通过广播变量为每个节点提供很大的输入数据集(高效)。 Spark还尝试使用高效的广播算法分发广播变量,以降低通信成本。
Spark的Actions可以分解为一系列的Stages(Stage通过Shuffle操作划分)Spark自动广播每个Stage的Task所需的common data。采用此方式广播的数据序列化之后缓存,然后在Task运行之前执行反序列化。
这意味着,显式创建广播变量仅在跨多个Stage的Task需要相同数据或者需要以反序列化格式缓存数据时才有用。
广播变量通过调用SparkContext.broadcast(v)创建广播变量v。广播变量是围绕v的包装器,其值可以通过调用value方法来访问。代码如下:
累加器
Accumulators are variables that are only “added” to through an associative and commutative operation and can therefore be efficiently supported in parallel.
它们可以用于实现计数器(类似MapReduce一样)或者求和,Spark原生支持数字类型的Accumulators,当然程序员也可以实现自定义的Accumulators。
用户可以创建实名/匿名的accumulators,实名accumulators在web UI,修改该accumulators的stage处可以看到accumulators变量的变化。具体如图: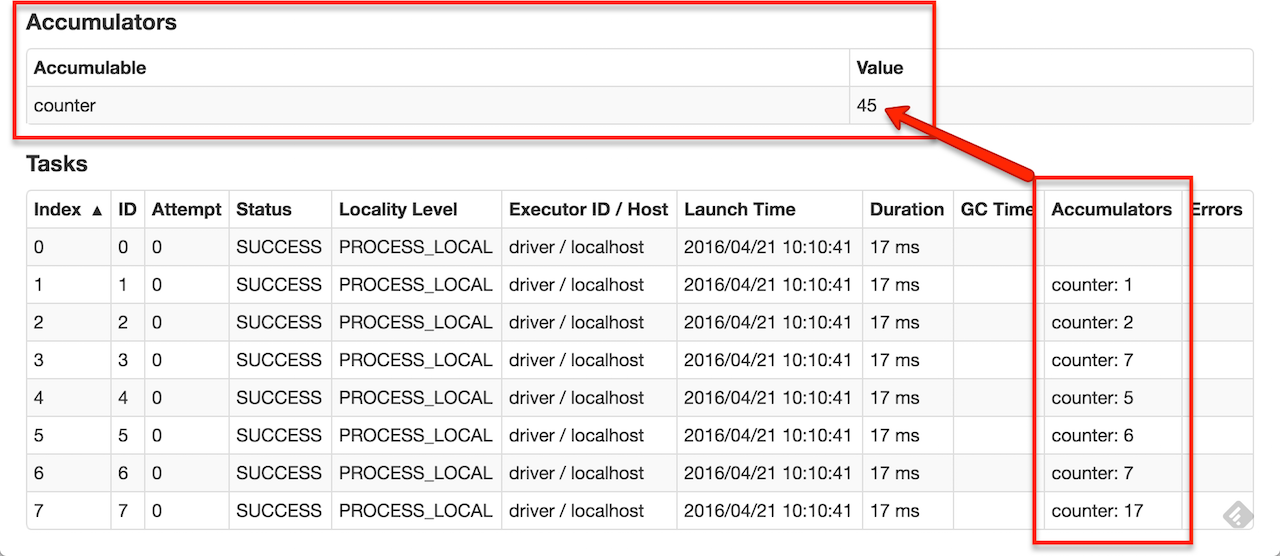
Tracking accumulators in the UI can be useful for understanding the progress of running stages.
程序员可以通过调用SparkContext.longAccumulator()或SparkContext.doubleAccumulator()来分别创建Long或Double类型的数字累加器。
然后集群运行这的Task可以调用add方法添加accumulators。 不过Task不能获取accumulators的值。 只有Driver可以使用value方法读取accumulators的值。
而实现自定义的accumulators,需要继承AccumulatorV2。代码如下:
注意:For accumulator updates performed inside actions only,即accumulator的更新需要Actions来触发计算。
提交任务到集群
|
|
通过Java/Scala启动Spark作业
The org.apache.spark.launcher package provides classes for launching Spark jobs as child processes using a simple Java API.
单元测试
Spark is friendly to unit testing with any popular unit test framework. Simply create a SparkContext in your test with the master URL set to local, run your operations, and then call SparkContext.stop() to tear it down. Make sure you stop the context within a finally block or the test framework’s tearDown method, as Spark does not support two contexts running concurrently in the same program.